

预测建模正在通过在问题升级之前识别过程问题来改变培养肉的生产。通过分析历史和实时数据,这些模型帮助操作员在细胞生长、分化和成熟等关键阶段保持最佳条件。这种主动的方法减少了失败,提高了产量,并确保了产品质量的一致性。
关键要点:
- 容易出现问题的阶段:营养耗尽、氧气短缺和剪切应力是常见风险。
- 模型类型:机械模型、数据驱动模型和混合模型提供了针对性的问题解决方案。
- 好处:早期故障检测、精确的根本原因分析和持续的过程优化。
- 数据需求:来自在线传感器和离线检测的高质量、多样化数据集至关重要。
- 技术:像PCA、PLS和数字孪生这样的工具可以增强预测和过程控制。
预测建模是一种数据驱动的解决方案,用于解决培养肉生产中的挑战,提供更好的一致性和运营效率。
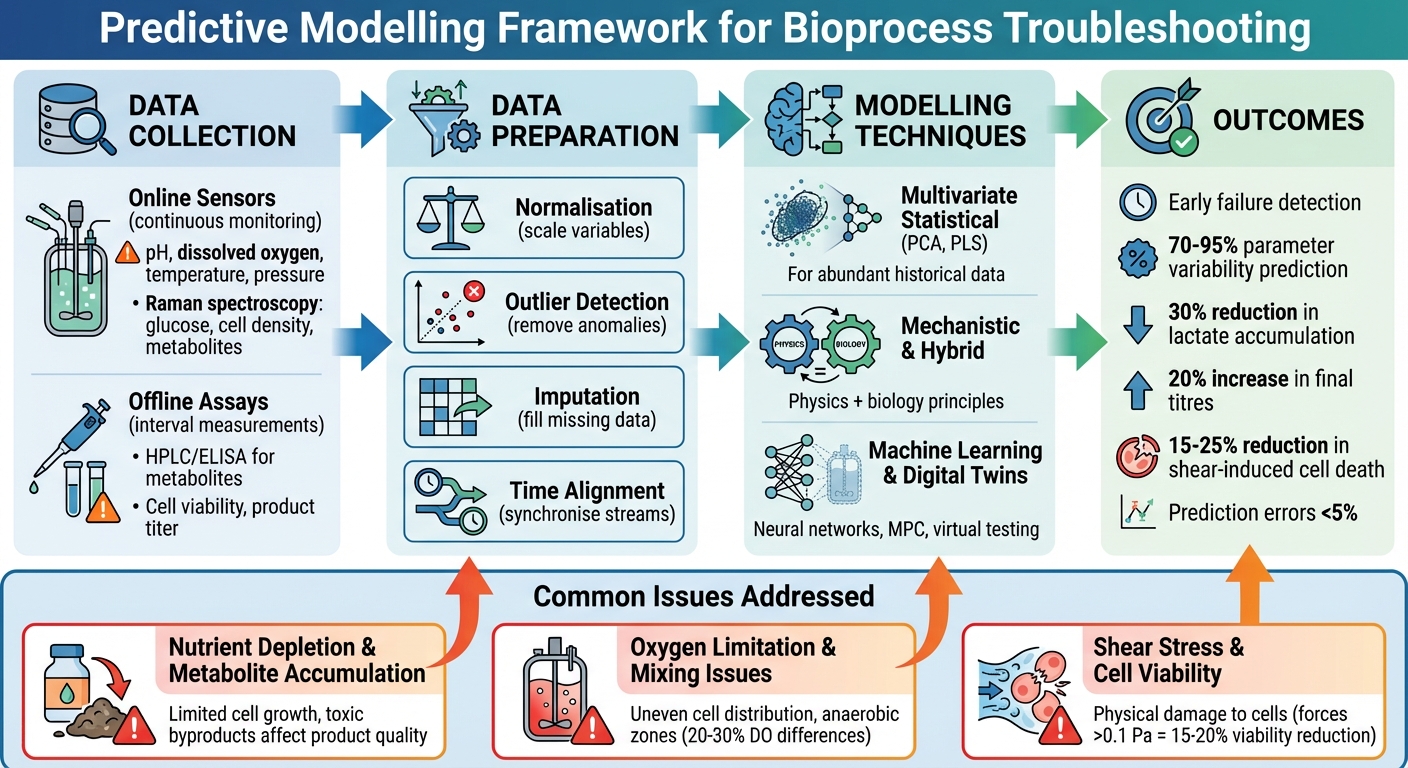
培养肉生物过程故障排除的预测建模框架
200: 掌握质量设计:从产品失败到生物制品CMC的商业成功
预测建模的数据要求
创建准确的预测模型取决于在生物过程中收集的数据的质量和范围。没有详细的数据集,模型无法预测故障或提高性能。捕捉生物反应器内的物理条件和细胞的生物行为是至关重要的。这个基础对于有效准备数据和应用建模技术至关重要。
培养肉类生物加工中的数据来源
预测模型依赖于两个主要数据来源:在线传感器和离线检测。
在线传感器持续监测实时参数,如pH值、溶解氧(DO)、温度和压力。一些先进的平台,如Sartorius ambr系统,甚至使用拉曼光谱法来跟踪葡萄糖水平、活细胞密度和代谢物[2][3]。这些传感器提供高频数据,捕捉生物反应器内发生的微小变化。
另一方面,离线检测在特定时间间隔提供精确测量。技术如HPLC或ELISA用于评估代谢物浓度(e.g,乳酸和氨)、细胞活力和产品滴度。虽然这些需要手动采样和实验室工作,但它们提供的精度水平是在线传感器可能无法始终实现的[2][3]。元数据,如进料策略和设定点,有助于解释传感器数据。例如,将拉曼光谱数据与进料曲线结合,可以让多变量模型预测关键质量属性,如最终滴度。这使得模型预测控制系统能够对生物工艺参数进行实时调整[2][3]。这种方法增强了模型解决问题和优化性能的能力。
一旦数据被收集,就必须仔细处理以确保其能够做出可靠的预测。
数据预处理技术
原始生物反应器数据很少能直接用于预测建模。在准备过程中需要进行几个预处理步骤:
- 归一化确保变量被缩放到可比较的范围。例如,它可以防止像细胞密度(通常具有较大值)这样的参数掩盖像pH值这样的小规模变量。此步骤对于偏最小二乘法(PLS)等算法尤为重要[3]。
- 异常值检测识别并去除由传感器噪声、采样错误或临时干扰引起的异常。通常使用统计阈值或基于PLS的方法来排除这些异常值,以防止它们影响预测[3]。
- 插补填补缺失的数据点。像回归插补(IBR)这样的技术使用参数之间的相关性——例如葡萄糖和乳酸水平——来估计空缺。如果缺少DO数据,模型可以根据pH值和葡萄糖之间的关系预测它,从而保持数据集在实时预测中的可靠性[3].
- 时间对齐同步可能不自然匹配的数据流。例如,连续的pH值读数需要与特定间隔进行的代谢物检测结果对齐。使用动态时间规整或线性插值等方法来确保正确对齐[3].
管理生物变异性
生物变异性是培养肉生产中最大的挑战之一。细胞系的差异、遗传漂移以及对营养缺乏的不同反应导致批次之间的生长速率和代谢物特征不一致[2][4][6]。这种变异性会显著影响预测的准确性。例如,如果模型没有设计为考虑细胞系或生产规模之间的差异,活细胞密度的预测可能会大相径庭。
为了解决这个问题,生产者应收集多样化的历史数据集,涵盖多个细胞系、培养基成分和生物反应器规模。多元统计过程控制(MSPC)可以通过将变异性分解为系统性和随机成分来帮助模型区分正常波动和实际问题[3][4][6]。
另一个有效的解决方案是使用混合模型。这些模型结合了机械知识——如用于细胞生长的Monod动力学——与数据驱动的方法。这种混合方法使模型能够捕捉到可预测的生物过程和纯粹机械模型可能遗漏的不可预测变化。此外,采用具有明确定义的无动物成分的无血清培养基有助于标准化营养成分。这减少了变异性,从而产生更一致的数据和更可靠的预测模型。 生物过程故障排除的建模技术 选择合适的建模方法取决于对过程的理解程度、可用数据的质量以及您希望预测的特定故障。每种技术都为培养肉类生物过程的故障排除带来了自身的优势,并与数据准备的早期步骤协同工作。
多变量统计模型
当历史数据丰富但生物过程尚未完全理解时,偏最小二乘法 (PLS) 和 主成分分析 (PCA) 等技术大放异彩。这些方法分析多个相互关联的变量 - 如温度、pH 值、溶解氧、搅拌速率和光谱数据 - 并将其提炼为代表正常过程行为的几个关键模式。
例如,PCA 使用成功批次的数据建立基线。如果新批次偏离此基线,像 Hotelling's T² 这样的统计数据可以及早发现潜在问题,使操作员能够在问题升级之前进行干预。PLS 更进一步,通过实时预测营养物和代谢物水平。相较于等待离线检测,PLS模型可以预测葡萄糖耗尽或乳酸积累等事件,从而更容易主动调整喂养时间表。
另一个有价值的工具,SIMCA,利用历史记录填补缺失数据,确保数据集中的空白不会妨碍故障排除。然而,这些模型的成功取决于用反映细胞系、培养基类型和生产规模变化的多样化数据集进行训练。这确保了操作员可以在培养肉生产过程中快速定位和解决偏差。
机理和混合模型
当对基础物理和生物学有深入理解时,机理模型 - 基于质量平衡和传输方程等原理构建 - 变得不可或缺。这些模型模拟生物反应器内的氧气传递、混合动力学和营养分布等关键参数。它们在扩大规模时特别有用,因为直接实验既昂贵又耗时。
在培养肉生产中,机械模型还可以预测剪切力如何影响附着在微载体或支架上的细胞。通过将流体动力学计算与细胞敏感性数据相结合,这些模型提供了关于搅拌或灌流变化如何影响细胞活力和组织质量的见解。这些预测对于解决转向新设备或扩大生产时的性能下降至关重要。
混合模型结合了机械和数据驱动方法的优势。它们使用机械框架来保持物理一致性,同时添加数据驱动组件——如神经网络或PLS——以解释尚未完全理解的复杂动力学。这对于培养肉尤其重要,因为关于3D支架中细胞分化的知识仍在发展中。机械部分确保在变化条件下的可靠预测,而数据驱动层适应现实世界的植物行为。这些混合模型为下一节讨论的复杂数字工具铺平了道路。
机器学习和数字孪生
神经网络擅长识别传感器数据与结果(如可行细胞密度或分化标记)之间的非线性关系。通过在历史数据上训练这些模型,它们可以作为早期预警系统,在问题升级为重大问题之前检测到异常。
模型预测控制 (MPC) 通过将预测模型嵌入优化过程更进一步。MPC 使得设定值的实时调整成为可能,研究表明它可以提高最终蛋白质产量和产品质量[8]。
数字孪生 - 物理生物反应器的虚拟复制品 - 结合这些建模技术来虚拟模拟和排除故障。它们允许操作员在无风险的环境中测试“假设”场景并评估纠正措施,然后再进行实际更改。随着培养肉生产过程变得更加标准化和设备更加统一,数字孪生预计将在常规故障排除和过程优化中发挥越来越重要的作用。
sbb-itb-ffee270
案例研究:预测建模的应用
工业细胞培养的例子展示了预测建模如何解决特定的生物工艺挑战,并为培养肉生产提供有价值的见解。
营养耗竭和代谢物积累
在生物加工中有效管理营养物质至关重要。某细胞培养设施的一项研究创建了一个结合多元线性回归和机器学习的预测模型。该模型旨在预测生产过程早期的关键输出,如最终滴定度、峰值活细胞密度、乳酸和氨水平。令人印象深刻的是,它解释了70-95%的参数变异性。通过在传统警报之前几天识别出有风险的批次,该模型实现了有针对性的干预,改善了性能并减少了变异性[11]。
在涉及补料分批工艺的另一个案例中,基于PLS(偏最小二乘)多变量模型的预测喂养策略实现了乳酸积累的30%减少。这一改进转化为最终滴定度的20%增加[3]。当与拉曼光谱等工具集成时(e.g., 在Sartorius ambr生物反应器中),葡萄糖、活细胞密度和代谢物的实时监测提供的预测误差小于5%[2][3]。这些方法可以适用于培养肉生产,其中精确的营养管理对于优化产量和控制成本至关重要。
氧气限制和混合问题
在生物加工中,维持足够的氧气水平和适当的混合是另一个关键挑战。计算流体动力学(CFD)模型被广泛用于模拟生物反应器中的氧气梯度和混合模式。在放大过程中,这些模拟识别出导致细胞培养中形成缺氧区的低效搅拌器设计。通过根据CFD结果调整搅拌速率,氧气传递效率提高了20-30%。一些研究报告称,在大型反应器的不同区域之间,溶解氧的差异超过20-30% [2][7][9]。
此外,一家生物制药制造商采用了由数字孪生模型驱动的模型预测控制(MPC)框架。这使得气体喷射的动态调整成为可能,有效解决了混合问题,并将产量提高了15% [3][6]。对于培养肉生产来说,均匀混合对于避免高密度培养中的营养梯度至关重要,这些策略在确保一致的组织质量方面具有重大潜力。
剪切应力和细胞活力
由搅拌器动作和搅拌系统中的碰撞引起的剪切应力,会显著影响细胞活力。预测模型已被用于量化这些机械力及其影响。在微载体培养中,识别出了应力阈值,超过0.1 Pa的力与锚定依赖性细胞的存活率降低15-20%相关[2][10]。通过优化珠子大小和搅拌速度,模型引导的调整将剪切引起的细胞死亡减少了25%,从而提高了超过2%的蛋白质产量和更好的产品质量[2][8][10]。
虽然在培养肉中的直接应用仍在发展中,但已提出类似的混合模型来模拟微载体动力学。这些模型可以帮助在扩展过程中将细胞存活率保持在90%以上[6]。这些示例展示了预测建模不仅解决了现有挑战,还实现了主动优化,为培育肉生产的改善结果铺平了道路。
未来方向和实施考虑
在成功案例的基础上,未来的培育肉生产策略必须专注于实施先进模型,配合尖端设备,并遵循标准化协议。
培育肉生产者的关键要点
为了使预测建模有效,需要三个关键组成部分。首先,集成传感器在同时分析关键参数中起着至关重要的作用,确保实时模型的效率。例如,拉曼光谱平台可以同时监测葡萄糖水平、活细胞密度和代谢物,从而实现精确的反馈控制策略[2][5]。这些集成平台简化了实时监测,简化了流程,并显著减少了浪费[2]。
其次,缩小实验允许在较小规模上开发出稳健的模型,然后再应用于商业生物反应器。这些模型必须保持高精度,有效处理噪声,并在放大时需要最少的重新校准[2]。借鉴细胞和基因治疗——具有类似挑战的领域——缩小数据必须通过生产规模的运行进行验证,以解决可靠性问题并确保无缝扩展[2]。最后,与ISA-88标准对齐的标准化数据协议是必不可少的。这些协议支持实时释放测试和自适应模型预测控制(MPC),帮助预测模型演变为处方分析工具[2][3]。这些策略共同解决了当前的挑战,并为新的进步打开了大门。
研究差距和机会
尽管取得了进展,但仍然存在一些挑战。一个主要问题是缺乏开放数据集,这阻碍了用于不同生物反应器类型和规模的强大、适应性模型的发展[2][3][4]。另一个挑战是模型的可转移性 - 许多模型在从实验室环境过渡到生产环境或应用于不同设备配置时无法始终如一地表现[2][3][4]。此外,模型预测与最终产品质量属性之间的联系较弱,例如细胞活力和整体产量[2][3][4]。
为了克服这些障碍,需要标准化的协议和共享的数据集来提高模型的适应性。AI驱动的放大模拟可以帮助预测更大规模下的行为,从而增强可转移性[4][10]。混合模型结合了数据驱动的方法和机械洞察力,在管理生物变异性方面提供了未开发的潜力[6]。通过先进的MPC和敏感性分析加强模型预测与质量属性之间的联系,可以实现闭环控制系统和过程调整的虚拟测试[3][6]。
解决这些差距需要投资于为可扩展性和精确性设计的设备。
设备和采购注意事项
为了预测建模的成功,能够创建数据丰富环境的专业设备是必不可少的。生产商应评估其设备是否支持集成传感器——如拉曼光谱设备——以及在容纳自动化控制(如MPC)的同时是否能够有效扩展。关键过程参数的可靠监测对于预测模型的最佳运行是必不可少的。
像第一个专门为培养肉行业设计的B2B市场这样的资源,可以简化采购。
常见问题
预测建模如何支持培养肉生产? 预测建模在改善培养肉生产中起着关键作用,它可以及早发现潜在的生物加工挑战,并在它们成为重大问题之前加以解决。这种前瞻性的方法有助于减少停机时间,提高效率,并保持一致的产品质量。 通过分析生物加工系统的数据,这些模型可以发现模式并预见问题,使研究人员和生产团队能够做出明智的调整。结果是?更高的产量、更少的浪费和更低的运营成本——所有这些都促成了更可持续和可靠的培养肉生产过程。在生物工艺故障排除中,有效预测建模需要哪些关键数据?
准确和详细的数据是生物工艺故障排除中有效预测建模的基础。最关键的监测因素包括温度、pH值、溶解氧、CO₂浓度、葡萄糖水平、生物量测量和代谢物谱。
收集这些变量的高质量、实时数据至关重要。它使研究人员和行业专业人士能够及早发现潜在问题,确保操作顺利并优化整体生物工艺性能。这种积极的方法有助于将故障降到最低,并保持流程高效运行。
混合模型如何改善培养肉类生物工艺中的故障排除?
混合模型通过将机制模型与数据驱动方法相结合,正在改变培养肉类生物工艺中的故障排除。这种组合为准确预测潜在问题和微调关键过程创造了一个强大的工具。
通过实时监控系统和及早识别问题,混合模型减少了中断并改善了过程管理。结果是?更高的效率、更高的产量和更可靠的生产系统。









