

Predictieve modellering transformeert de productie van gekweekt vlees door procesproblemen te identificeren voordat ze escaleren. Door historische en real-time gegevens te analyseren, helpen deze modellen operators om optimale omstandigheden te handhaven in belangrijke stadia zoals celgroei, differentiatie en rijping. Deze proactieve benadering vermindert mislukkingen, verbetert de opbrengsten en zorgt voor consistente productkwaliteit.
Belangrijkste punten:
- Stadia gevoelig voor problemen: Voedingsstofuitputting, zuurstoftekorten en schuifspanning zijn veelvoorkomende risico's.
- Modeltypen: Mechanistische, data-gedreven en hybride modellen bieden op maat gemaakte oplossingen voor probleemoplossing.
- Voordelen: Vroege foutdetectie, nauwkeurige oorzaak-analyse en geautomatiseerde procescontrole.
- Gegevensbehoeften: Hoogwaardige, diverse datasets van online sensoren en offline tests zijn cruciaal.
- Technieken: Tools zoals PCA, PLS en digitale tweelingen verbeteren voorspellingen en procescontrole.
Voorspellende modellering is een data-gedreven oplossing voor het aanpakken van uitdagingen in de productie van gekweekt vlees, met verbeterde consistentie en operationele efficiëntie.
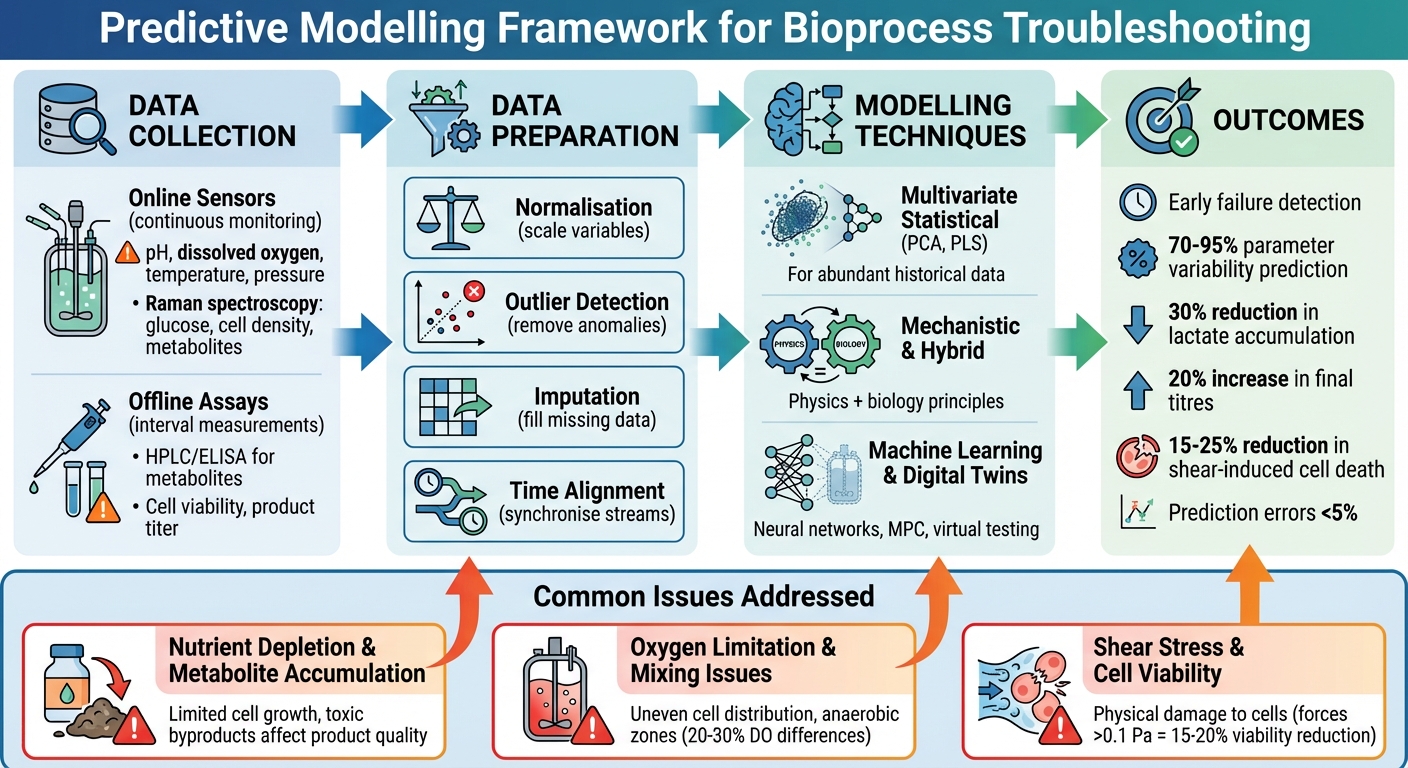
Voorspellend Modellering Framework voor Probleemoplossing in Gekweekt Vlees Bioprocessen
200: Beheersing van Kwaliteit door Ontwerp: Van Productfalen tot Commercieel Succes in Biologics CMC De...
Data Vereisten voor Voorspellende Modellering
Het creëren van nauwkeurige voorspellende modellen hangt af van de kwaliteit en reikwijdte van de data die tijdens het bioproces worden verzameld. Zonder gedetailleerde datasets is het onmogelijk voor modellen om falen te voorspellen of prestaties te verbeteren. Het is essentieel om zowel de fysieke omstandigheden binnen de bioreactor als het biologische gedrag van de cellen vast te leggen.Deze basis is cruciaal voor het voorbereiden van gegevens en het effectief toepassen van modelleertechnieken.
Gegevensbronnen in Gekweekt Vlees Bioprocessen
Voorspellende modellen zijn afhankelijk van twee primaire gegevensbronnen: online sensoren en offline assays.
Online sensoren monitoren continu real-time parameters zoals pH, opgelost zuurstof (DO), temperatuur en druk. Sommige geavanceerde platforms, zoals Sartorius ambr systemen, gebruiken zelfs Raman-spectroscopie om glucosewaarden, levensvatbare cel dichtheid en metabolieten te volgen [2][3]. Deze sensoren leveren gegevens met hoge frequentie, waarbij de kleine veranderingen in de bioreactor worden vastgelegd.
Offline assays daarentegen leveren nauwkeurige metingen op specifieke intervallen. Technieken zoals HPLC of ELISA worden gebruikt om metabolietconcentraties te beoordelen (e.g. , lactaat en ammoniak), cel levensvatbaarheid en product titer.Hoewel deze handmatige bemonstering en laboratoriumwerk vereisen, bieden ze een precisieniveau dat online sensoren mogelijk niet altijd bereiken[2][3]. Metadata, zoals voedingsstrategieën en setpoints, helpen bij het interpreteren van sensorgegevens. Bijvoorbeeld, het combineren van Raman-spectroscopiegegevens met voedingsprofielen stelt multivariate modellen in staat om kritische kwaliteitskenmerken te voorspellen, zoals de uiteindelijke titer. Dit stelt modelvoorspellende regelsystemen in staat om in real-time aanpassingen te maken aan bioprocesparameters[2][3]. Dergelijke benaderingen verbeteren het vermogen van modellen om problemen op te lossen en prestaties te optimaliseren.
Zodra de gegevens zijn verzameld, moeten ze zorgvuldig worden verwerkt om ervoor te zorgen dat ze betrouwbare voorspellingen kunnen doen.
Technieken voor Gegevensvoorverwerking
Ruwe bioreactorgegevens zijn zelden klaar voor gebruik in voorspellende modellering.Verschillende pre-processing stappen zijn noodzakelijk om het voor te bereiden:
- Normalisatie zorgt ervoor dat variabelen worden geschaald naar vergelijkbare bereiken. Bijvoorbeeld, het voorkomt dat parameters zoals cel dichtheid (die vaak grotere waarden heeft) kleinere schaalvariabelen zoals pH overschaduwen. Deze stap is vooral belangrijk voor algoritmen zoals partial least squares (PLS) [3].
- Outlier detectie identificeert en verwijdert anomalieën veroorzaakt door sensorgeluid, bemonsteringsfouten of tijdelijke verstoringen. Statistische drempels of PLS-gebaseerde methoden worden vaak gebruikt om deze uitschieters uit te sluiten, zodat ze voorspellingen niet vertekenen [3].
- Imputatie vult ontbrekende datapunten in. Technieken zoals imputatie door regressie (IBR) gebruiken correlaties tussen parameters - bijvoorbeeld glucose- en lactaatniveaus - om hiaten te schatten.Als DO-gegevens ontbreken, kan het model deze voorspellen op basis van relaties tussen pH en glucose, waardoor de betrouwbaarheid van de dataset voor realtime voorspellingen behouden blijft [3].
- Tijduitlijning synchroniseert datastromen die mogelijk niet van nature overeenkomen. Bijvoorbeeld, continue pH-metingen moeten worden afgestemd op metabolietassayresultaten die op specifieke intervallen worden genomen. Methoden zoals dynamische tijdsvervorming of lineaire interpolatie worden gebruikt om een juiste uitlijning te garanderen [3].
Beheer van Biologische Variabiliteit
Biologische variabiliteit vormt een van de grootste uitdagingen in de productie van gekweekt vlees. Verschillen in cellijnen, genetische drift en uiteenlopende reacties op nutriëntentekorten leiden tot inconsistenties in groeisnelheden en metabolietprofielen van batch tot batch[2][4][6]. Deze variabiliteit kan de nauwkeurigheid van voorspellingen aanzienlijk beïnvloeden. Bijvoorbeeld, als een model niet is ontworpen om rekening te houden met verschillen tussen cellijnen of productieschalen, kunnen voorspellingen voor de levensvatbare cel dichtheid ver naast de waarheid liggen.
Om dit aan te pakken, moeten producenten diverse historische datasets verzamelen die meerdere cellijnen, mediacomposities en bioreactorschalen omvatten. Multivariate statistische procescontrole (MSPC) kan helpen door variabiliteit op te splitsen in systematische en willekeurige componenten, waardoor modellen normale schommelingen kunnen onderscheiden van daadwerkelijke problemen [3][4][6].
Een andere effectieve oplossing is het gebruik van hybride modellen. Deze combineren mechanistische kennis - zoals Monod-kinetiek voor celgroei - met data-gedreven methoden.Deze mix stelt modellen in staat om zowel de voorspelbare biologische processen als de onvoorspelbare variaties vast te leggen die puur mechanistische modellen mogelijk missen[3][4][6]. Bovendien helpt het aannemen van serumvrije media met goed gedefinieerde, dierlijke-vrije formuleringen om de voedingssamenstellingen te standaardiseren. Dit vermindert variabiliteit, wat resulteert in consistentere data en betrouwbaardere voorspellende modellen [1].
Modelleringstechnieken voor Bioprocesproblemen oplossen
Het selecteren van de juiste modelleringsaanpak hangt af van hoe goed het proces wordt begrepen, de kwaliteit van de beschikbare gegevens en de specifieke fouten die u wilt voorspellen. Elke techniek brengt zijn eigen sterke punten mee voor het oplossen van problemen in gekweekte vleesbioprocessen, en ze werken in harmonie met de eerdere stappen van gegevensvoorbereiding.
Multivariate Statistische Modellen
Wanneer historische gegevens overvloedig zijn maar de biologische processen niet volledig worden begrepen, komen technieken zoals Partial Least Squares (PLS) en Principal Component Analysis (PCA) naar voren. Deze methoden analyseren meerdere onderling gerelateerde variabelen - zoals temperatuur, pH-niveaus, opgelost zuurstof, roersnelheden en spectroscopiegegevens - en destilleren ze tot een paar belangrijke patronen die het normale procesgedrag vertegenwoordigen.
Bijvoorbeeld, PCA stelt een basislijn vast met behulp van gegevens van succesvolle batches. Als een nieuwe batch van deze basislijn afwijkt, kunnen statistieken zoals Hotelling's T² potentiële problemen vroegtijdig signaleren, waardoor operators kunnen ingrijpen voordat problemen escaleren. PLS gaat nog een stap verder door realtime voorspellingen van nutriënten- en metabolietniveaus mogelijk te maken.In plaats van te wachten op offline assays, kunnen PLS-modellen gebeurtenissen voorspellen zoals glucose-uitputting of lactaatopbouw, waardoor het gemakkelijker wordt om voederschema's proactief aan te passen.
Een ander waardevol hulpmiddel, SIMCA, vult ontbrekende gegevens aan met behulp van historische records, zodat hiaten in datasets het oplossen van problemen niet belemmeren. Het succes van deze modellen hangt echter af van het trainen ervan met diverse datasets die de variabiliteit over cellijnen, mediatypen en productieschalen weerspiegelen. Dit zorgt ervoor dat operators snel afwijkingen kunnen lokaliseren en aanpakken tijdens de productie van gekweekt vlees.
Mechanistische en Hybride Modellen
Wanneer er een goed begrip is van de onderliggende fysica en biologie, worden mechanistische modellen - gebaseerd op principes zoals massabalansen en transportequaties - onmisbaar. Deze modellen simuleren belangrijke parameters zoals zuurstofoverdracht, mengdynamiek en nutriëntenverdeling binnen bioreactoren.Ze zijn bijzonder nuttig tijdens opschaling, waar directe experimenten kostbaar en tijdrovend zijn.
Bij de productie van gekweekt vlees kunnen mechanistische modellen ook voorspellen hoe schuifkrachten cellen beïnvloeden die aan microcarriers of steigers zijn bevestigd. Door hydrodynamische berekeningen te integreren met gegevens over celsensitiviteit, bieden deze modellen inzicht in hoe veranderingen in agitatie of perfusie de celviabiliteit en weefselkwaliteit kunnen beïnvloeden. Dergelijke voorspellingen zijn cruciaal voor het aanpakken van prestatieverminderingen bij de overgang naar nieuwe apparatuur of het opschalen van de productie.
Hybride modellen combineren de sterke punten van mechanistische en data-gedreven benaderingen. Ze gebruiken een mechanistisch kader voor fysieke consistentie terwijl ze data-gedreven componenten toevoegen - zoals neurale netwerken of PLS - om rekening te houden met complexe kinetiek die niet volledig wordt begrepen.Dit is vooral relevant voor gekweekt vlees, waar kennis over cel differentiatie in 3D-skeletten nog in ontwikkeling is. Het mechanistische deel zorgt voor betrouwbare voorspellingen onder veranderende omstandigheden, terwijl de data-gedreven laag zich aanpast aan het gedrag van echte planten. Deze hybride modellen banen de weg voor geavanceerde digitale tools die in de volgende sectie worden besproken.
Machine Learning en Digitale Tweelingen
Neurale netwerken excelleren in het identificeren van niet-lineaire relaties tussen sensorgegevens en uitkomsten zoals levensvatbare celdichtheid of differentiatiemarkers. Door deze modellen te trainen op historische gegevens, kunnen ze fungeren als vroege waarschuwingssystemen, die anomalieën detecteren voordat ze escaleren tot significante problemen.
Model Predictive Control (MPC) gaat een stap verder door voorspellende modellen in optimalisatieprocessen te integreren.MPC maakt realtime aanpassingen aan setpoints mogelijk, en studies hebben aangetoond dat het de uiteindelijke eiwitopbrengsten en productkwaliteit kan verbeteren [8].
Digitale tweelingen - virtuele replica's van fysieke bioreactoren - combineren deze modelleringstechnieken om processen virtueel te simuleren en problemen op te lossen. Ze stellen operators in staat om "wat-als" scenario's te testen en corrigerende maatregelen te evalueren in een risicovrije omgeving voordat er veranderingen in de echte wereld worden doorgevoerd. Naarmate de productieprocessen van gekweekt vlees meer gestandaardiseerd worden en de apparatuur uniformer, wordt verwacht dat digitale tweelingen een steeds belangrijkere rol zullen spelen in routinematige probleemoplossing en procesoptimalisatie.
sbb-itb-ffee270
Case Studies: Toepassingen van Predictive Modelling
Voorbeelden uit industriële celcultuur laten zien hoe voorspellende modellering specifieke bioprocesuitdagingen kan aanpakken en waardevolle inzichten kan bieden voor de productie van gekweekt vlees.
Nutriëntendepletie en Metabolietaccumulatie
Het effectief beheren van nutriënten is cruciaal in bioprocessing. Een studie van een celkweekfaciliteit creëerde een voorspellend model dat meervoudige lineaire regressie combineerde met machine learning. Dit model was ontworpen om belangrijke outputs zoals eindtiter, piek van de levensvatbare cel dichtheid, lactaat- en ammoniakniveaus vroeg in het productieproces te voorspellen. Indrukwekkend genoeg verklaarde het 70–95% van de parameter variabiliteit. Door risicovolle batches dagen voor traditionele alarmen te identificeren, maakte het model gerichte interventies mogelijk, wat de prestaties verbeterde en de variabiliteit verminderde [11].
In een ander geval met fed-batch processen, bereikten voorspellende voedingsstrategieën gebaseerd op PLS (partial least squares) multivariate modellen een 30% vermindering in lactaataccumulatie. Deze verbetering vertaalde zich in een 20% toename in eindtiters [3]. Wanneer geïntegreerd met tools zoals Raman-spectroscopie (e.g. , in Sartorius ambr-bioreactoren), leverde real-time monitoring van glucose, levensvatbare cel dichtheid en metabolieten voorspellingsfouten van minder dan 5% op [2] [3]. Deze benaderingen kunnen worden aangepast voor de productie van gekweekt vlees, waar nauwkeurig nutriëntenbeheer essentieel is voor het optimaliseren van de opbrengst en het beheersen van de kosten.
Zuurstofbeperking en mengproblemen
Het handhaven van voldoende zuurstofniveaus en een goede menging is een andere kritieke uitdaging in bioprocessing. Computationele vloeistofdynamica (CFD) modellen worden veel gebruikt om zuurstofgradiënten en mengpatronen in bioreactoren te simuleren. Tijdens opschaling hebben deze simulaties inefficiënte roerderontwerpen geïdentificeerd die hypoxische zones in celculturen creëren. Door de roersnelheden aan te passen op basis van CFD-bevindingen, verbeterde de zuurstofoverdrachtsefficiëntie met 20–30%.Sommige studies rapporteerden verschillen in opgeloste zuurstof van meer dan 20-30% tussen verschillende zones in grote reactoren [2][7][9].
Bovendien gebruikte een fabrikant van biologische producten een modelvoorspellend regelkader (MPC) aangedreven door digitale tweelingmodellen. Dit maakte dynamische aanpassingen aan gasbeluchting mogelijk, waardoor mengproblemen effectief werden opgelost en de opbrengsten met 15% werden verhoogd [3][6]. Voor de productie van gekweekt vlees, waar uniforme menging essentieel is om nutriëntengradienten in hoge-dichtheidsculturen te vermijden, bieden deze strategieën veelbelovende mogelijkheden om consistente weefselkwaliteit te waarborgen.
Schuifspanning en Cellevensvatbaarheid
Schuifspanning, veroorzaakt door de werking van de roerder en botsingen in geroerde systemen, kan een aanzienlijke impact hebben op de levensvatbaarheid van cellen.Voorspellende modellen zijn gebruikt om deze mechanische krachten en hun effecten te kwantificeren. In microcarrier culturen, werden stressdrempels geïdentificeerd, waarbij krachten van meer dan 0,1 Pa gekoppeld zijn aan 15-20% vermindering in levensvatbaarheid voor aanhechtingsafhankelijke cellen [2][10]. Door het optimaliseren van kraalgroottes en roersnelheden, verminderden modelgeleide aanpassingen de door schuif veroorzaakte celdood met 25%, wat resulteerde in meer dan 2% hogere eiwitopbrengsten en betere productkwaliteit [2][8][10].
Hoewel directe toepassingen in gekweekt vlees nog in ontwikkeling zijn, zijn vergelijkbare hybride modellen voorgesteld om microcarrier dynamiek te simuleren. Deze zouden kunnen helpen om de cellevensvatbaarheid boven de 90% te houden tijdens de expansie [6]. Deze voorbeelden tonen aan hoe voorspellende modellering niet alleen bestaande uitdagingen aanpakt, maar ook proactieve optimalisatie mogelijk maakt, wat de weg vrijmaakt voor verbeterde resultaten in de productie van gekweekt vlees.
Toekomstige Richtingen en Implementatie Overwegingen
Voortbouwend op succesvolle casestudy's moeten toekomstige strategieën in de productie van gekweekt vlees zich richten op het implementeren van geavanceerde modellen naast geavanceerde apparatuur en het naleven van gestandaardiseerde protocollen.
Belangrijke Inzichten voor Producenten van Gekweekt Vlees
Voor voorspellende modellering om effectief te zijn, zijn drie kritische componenten vereist. Ten eerste spelen geïntegreerde sensoren een cruciale rol bij het gelijktijdig analyseren van essentiële parameters, wat zorgt voor real-time model efficiëntie.Bijvoorbeeld, Raman-spectroscopieplatforms kunnen glucosewaarden, levensvatbare cel dichtheid en metabolieten tegelijkertijd monitoren, waardoor nauwkeurige feedback-controlestrategieën mogelijk worden [2] [5]. Deze geïntegreerde platforms vereenvoudigen real-time monitoring, stroomlijnen processen en verminderen afval aanzienlijk [2].
Ten tweede, schalen-down modellering maakt het mogelijk om robuuste modellen op kleinere schaal te ontwikkelen voordat ze worden toegepast op commerciële bioreactoren. Deze modellen moeten een hoge precisie behouden, effectief omgaan met ruis en minimale herkalibratie vereisen bij opschaling [2] . Door parallellen te trekken met cel- en gentherapie - velden met vergelijkbare uitdagingen - moeten schaal-down gegevens worden gevalideerd door middel van productie op schaal om betrouwbaarheidsproblemen aan te pakken en naadloze opschaling te garanderen [2]. Ten slotte zijn gestandaardiseerde gegevensprotocollen die in lijn zijn met ISA-88 normen essentieel. Deze protocollen maken real-time vrijgavetesten en adaptieve modelvoorspellende controle (MPC) mogelijk, waardoor voorspellende modellen kunnen evolueren naar prescriptieve analysetools [2] [3]. Samen pakken deze strategieën huidige uitdagingen aan en openen ze de deur naar nieuwe ontwikkelingen.
Onderzoekshiaten en kansen
Ondanks de vooruitgang blijven er verschillende uitdagingen bestaan. Een belangrijk probleem is het gebrek aan open datasets, wat de ontwikkeling van robuuste, aanpasbare modellen voor gebruik in verschillende typen en schalen van bioreactoren belemmert [2][3][4]. Een andere uitdaging is model overdraagbaarheid - veel modellen presteren niet consistent bij de overgang van laboratoriumomgevingen naar productieomgevingen of wanneer ze worden toegepast op verschillende apparatuurconfiguraties [2] [3][4]. Bovendien is er een zwakke verbinding tussen modelvoorspellingen en uiteindelijke productkwaliteitskenmerken, zoals cel levensvatbaarheid en algehele opbrengst [2][3][4].
Om deze hindernissen te overwinnen, zijn gestandaardiseerde protocollen en gedeelde datasets nodig om de aanpasbaarheid van modellen te verbeteren. AI-gedreven opschalingssimulaties kunnen helpen om gedrag op grotere schaal te voorspellen, waardoor de overdraagbaarheid wordt verbeterd [4][10]. Hybride modellen, die data-gedreven benaderingen combineren met mechanistische inzichten, bieden onbenut potentieel voor het beheren van biologische variabiliteit [6]. Het versterken van de link tussen modelvoorspellingen en kwaliteitskenmerken door middel van geavanceerde MPC en gevoeligheidsanalyse kan gesloten-lus controlesystemen en virtuele tests voor procesaanpassingen mogelijk maken [3][6].
Het aanpakken van deze hiaten vereist investeringen in apparatuur die is ontworpen voor schaalbaarheid en precisie.
Overwegingen voor Apparatuur en Inkoop
Voor het succes van voorspellende modellering is gespecialiseerde apparatuur die in staat is om data-rijke omgevingen te creëren essentieel.Producenten moeten evalueren of hun apparatuur geïntegreerde sensoren ondersteunt - zoals Raman-spectroscopieapparaten - en of het effectief kan opschalen terwijl het geautomatiseerde besturingen zoals MPC kan accommoderen [2][3]. Betrouwbare monitoring van kritieke procesparameters is een must voor voorspellende modellen om optimaal te functioneren.
Een hulpmiddel zoals
Veelgestelde Vragen
Hoe ondersteunt voorspellende modellering de productie van gekweekt vlees?
Voorspellende modellering speelt een sleutelrol in het verbeteren van de productie van gekweekt vlees door potentiële bioprocesuitdagingen vroegtijdig te signaleren en aan te pakken voordat ze grote problemen worden. Deze vooruitstrevende benadering helpt om stilstand te verminderen, de efficiëntie te verbeteren en een consistente productkwaliteit te behouden.
Door gegevens van bioprocessystemen te onderzoeken, kunnen deze modellen patronen ontdekken en problemen voorzien, waardoor onderzoekers en productieteams weloverwogen aanpassingen kunnen maken. Het resultaat? Hogere opbrengsten, minder verspilling en lagere operationele kosten - alles draagt bij aan een duurzamer en betrouwbaarder productieproces van gekweekt vlees.
Welke gegevens zijn cruciaal voor effectieve voorspellende modellering bij het oplossen van problemen in bioprocessen?
Nauwkeurige en gedetailleerde gegevens vormen de ruggengraat van effectieve voorspellende modellering bij het oplossen van problemen in bioprocessen. De meest kritische factoren om te monitoren zijn temperatuur, pH-waarden, opgeloste zuurstof, CO₂-concentraties, glucosewaarden, biomassametingen, en metabolietprofielen.
Het verzamelen van hoogwaardige, real-time gegevens over deze variabelen is cruciaal. Het stelt onderzoekers en professionals in de industrie in staat om potentiële problemen vroegtijdig te signaleren, waardoor soepele operaties worden gegarandeerd en de algehele bioprocesprestaties worden geoptimaliseerd. Deze proactieve benadering helpt om mislukkingen te minimaliseren en zorgt ervoor dat processen efficiënt blijven verlopen.
Hoe verbeteren hybride modellen het oplossen van problemen in bioprocessen voor gekweekt vlees?
Hybride modellen transformeren het oplossen van problemen in bioprocessen voor gekweekt vlees door mechanistische modellen te combineren met data-gedreven methoden. Deze combinatie creëert een krachtig hulpmiddel voor het maken van nauwkeurige voorspellingen over potentiële problemen en het verfijnen van kritieke processen.
Met de mogelijkheid om systemen in realtime te monitoren en problemen vroegtijdig te identificeren, verminderen hybride modellen verstoringen en verbeteren ze het procesbeheer. Het resultaat? Grotere efficiëntie, hogere opbrengsten en betrouwbaardere productiesystemen.









