

Predictive modelling is transforming cultivated meat production by identifying process issues before they escalate. By analysing historical and real-time data, these models help operators maintain optimal conditions across key stages like cell growth, differentiation, and maturation. This proactive approach reduces failures, improves yields, and ensures consistent product quality.
Key takeaways:
- Stages prone to issues: Nutrient depletion, oxygen shortages, and shear stress are common risks.
- Model types: Mechanistic, data-driven, and hybrid models offer tailored solutions for troubleshooting.
- Benefits: Early failure detection, precise root-cause analysis, and automated process control.
- Data needs: High-quality, diverse datasets from online sensors and offline assays are critical.
- Techniques: Tools like PCA, PLS, and digital twins enhance predictions and process control.
Predictive modelling is a data-driven solution for tackling challenges in cultivated meat production, offering improved consistency and operational efficiency.
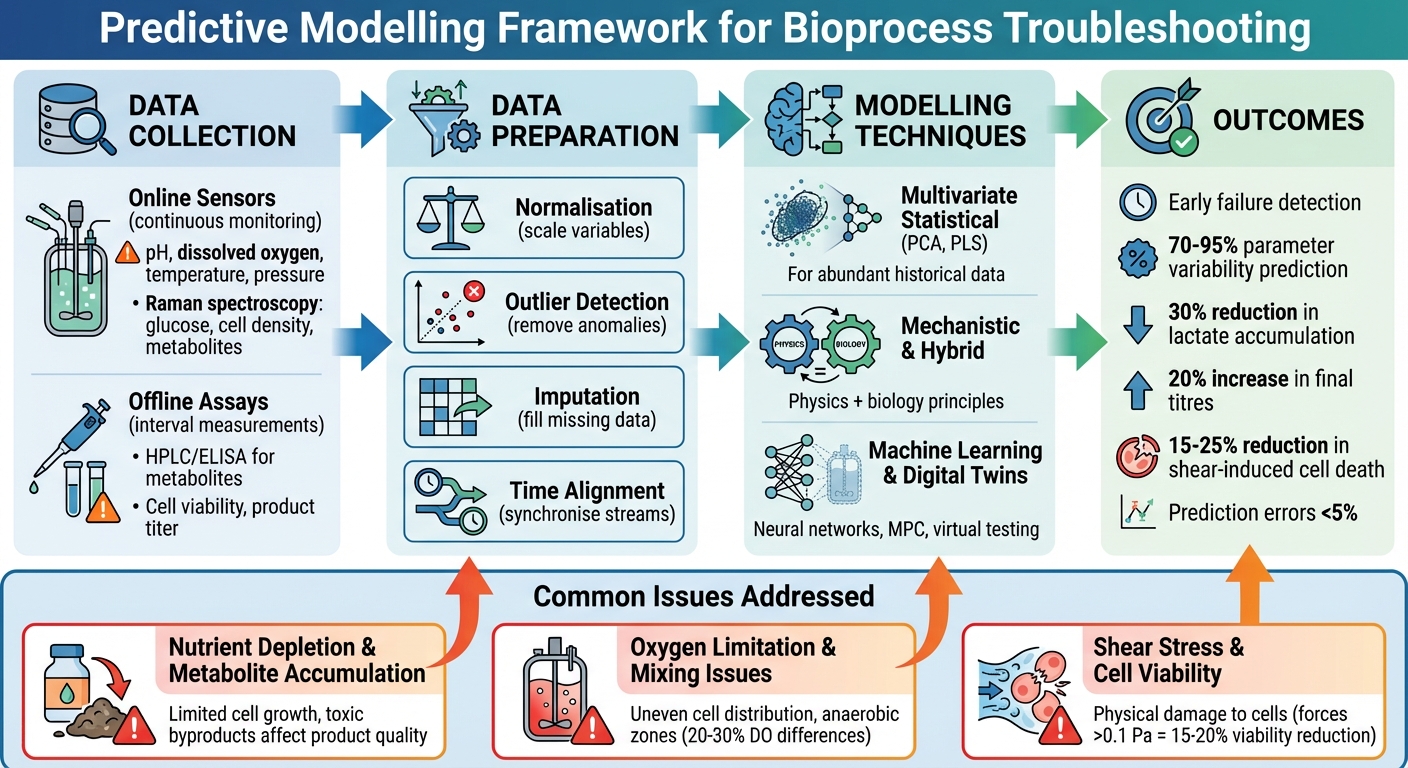
Predictive Modelling Framework for Cultivated Meat Bioprocess Troubleshooting
200: Mastering Quality by Design: From Product Failures to Commercial Success in Biologics CMC De...
Data Requirements for Predictive Modelling
Creating accurate predictive models hinges on the quality and range of data gathered during the bioprocess. Without detailed datasets, it's impossible for models to predict failures or improve performance. It's essential to capture both the physical conditions inside the bioreactor and the biological behaviours of the cells. This foundation is crucial for preparing data and applying modelling techniques effectively.
Data Sources in Cultivated Meat Bioprocesses
Predictive models rely on two primary data sources: online sensors and offline assays.
Online sensors continuously monitor real-time parameters like pH, dissolved oxygen (DO), temperature, and pressure. Some advanced platforms, such as Sartorius ambr systems, even use Raman spectroscopy to track glucose levels, viable cell density, and metabolites[2][3]. These sensors provide high-frequency data, capturing the minute changes occurring within the bioreactor.
Offline assays, on the other hand, deliver precise measurements at specific intervals. Techniques like HPLC or ELISA are used to assess metabolite concentrations (e.g., lactate and ammonia), cell viability, and product titer. While these require manual sampling and lab work, they offer a level of precision that online sensors might not always achieve[2][3]. Metadata, such as feed strategies and setpoints, help interpret sensor data. For instance, combining Raman spectroscopy data with feeding profiles allows multivariate models to predict critical quality attributes, such as final titer. This enables model predictive control systems to make real-time adjustments to bioprocess parameters[2][3]. Such approaches enhance the ability of models to troubleshoot and optimise performance.
Once the data is collected, it must be carefully processed to ensure it can make reliable predictions.
Data Pre-Processing Techniques
Raw bioreactor data is rarely ready for use in predictive modelling. Several pre-processing steps are necessary to prepare it:
- Normalisation ensures that variables are scaled to comparable ranges. For example, it prevents parameters like cell density (which often has larger values) from overshadowing smaller-scale variables like pH. This step is especially important for algorithms such as partial least squares (PLS)[3].
- Outlier detection identifies and removes anomalies caused by sensor noise, sampling errors, or temporary disturbances. Statistical thresholds or PLS-based methods are commonly used to exclude these outliers, preventing them from skewing predictions[3].
- Imputation fills in missing data points. Techniques like imputation by regression (IBR) use correlations between parameters - for instance, glucose and lactate levels - to estimate gaps. If DO data is missing, the model can predict it based on relationships between pH and glucose, preserving the dataset’s reliability for real-time forecasting[3].
- Time alignment synchronises data streams that may not naturally match up. For example, continuous pH readings need to align with metabolite assay results taken at specific intervals. Methods like dynamic time warping or linear interpolation are used to ensure proper alignment[3].
Managing Biological Variability
Biological variability presents one of the biggest challenges in cultivated meat production. Differences in cell lines, genetic drift, and varied reactions to nutrient shortages lead to inconsistencies in growth rates and metabolite profiles from batch to batch[2][4][6]. This variability can significantly impact the accuracy of predictions. For instance, if a model isn't designed to account for differences between cell lines or production scales, predictions for viable cell density can be way off.
To tackle this, producers should collect diverse historical datasets that cover multiple cell lines, media compositions, and bioreactor scales. Multivariate statistical process control (MSPC) can help by breaking down variability into systematic and random components, enabling models to distinguish normal fluctuations from actual issues[3][4][6].
Another effective solution is the use of hybrid models. These combine mechanistic knowledge - like Monod kinetics for cell growth - with data-driven methods. This blend allows models to capture both the predictable biological processes and the unpredictable variations that purely mechanistic models might miss[3][4][6]. Additionally, adopting serum-free media with well-defined, animal-free formulations helps standardise nutrient compositions. This reduces variability, resulting in more consistent data and more dependable predictive models[1].
Modelling Techniques for Bioprocess Troubleshooting
Selecting the right modelling approach depends on how well the process is understood, the quality of available data, and the specific failures you aim to predict. Each technique brings its own strengths to troubleshooting cultivated meat bioprocesses, and they work in harmony with the earlier steps of data preparation.
Multivariate Statistical Models
When historical data is abundant but the biological processes are not fully understood, techniques like Partial Least Squares (PLS) and Principal Component Analysis (PCA) shine. These methods analyse multiple interrelated variables - such as temperature, pH levels, dissolved oxygen, agitation rates, and spectroscopy data - and distil them into a few key patterns that represent normal process behaviour.
For instance, PCA establishes a baseline using data from successful batches. If a new batch deviates from this baseline, statistics like Hotelling's T² can flag potential issues early, allowing operators to intervene before problems escalate. PLS takes this a step further by enabling real-time predictions of nutrient and metabolite levels. Instead of waiting for offline assays, PLS models can forecast events like glucose depletion or lactate buildup, making it easier to adjust feeding schedules proactively.
Another valuable tool, SIMCA, fills in missing data using historical records, ensuring that gaps in datasets don’t hinder troubleshooting. However, the success of these models depends on training them with diverse datasets that reflect the variability across cell lines, media types, and production scales. This ensures operators can quickly pinpoint and address deviations during cultivated meat production.
Mechanistic and Hybrid Models
When there’s a solid understanding of the underlying physics and biology, mechanistic models - built on principles like mass balances and transport equations - become indispensable. These models simulate key parameters such as oxygen transfer, mixing dynamics, and nutrient distribution within bioreactors. They’re particularly useful during scale-up, where direct experimentation is costly and time-consuming.
In cultivated meat production, mechanistic models can also predict how shear forces impact cells attached to microcarriers or scaffolds. By integrating hydrodynamic calculations with data on cell sensitivity, these models provide insights into how changes in agitation or perfusion might affect cell viability and tissue quality. Such predictions are crucial for addressing performance drops when transitioning to new equipment or scaling up production.
Hybrid models combine the strengths of mechanistic and data-driven approaches. They use a mechanistic framework for physical consistency while adding data-driven components - like neural networks or PLS - to account for complex kinetics that aren’t fully understood. This is especially relevant for cultivated meat, where knowledge about cell differentiation in 3D scaffolds is still developing. The mechanistic part ensures reliable predictions under changing conditions, while the data-driven layer adapts to real-world plant behaviour. These hybrid models pave the way for sophisticated digital tools discussed in the next section.
Machine Learning and Digital Twins
Neural networks excel at identifying nonlinear relationships between sensor data and outcomes such as viable cell density or differentiation markers. By training these models on historical data, they can act as early-warning systems, detecting anomalies before they escalate into significant issues.
Model Predictive Control (MPC) takes this a step further by embedding predictive models into optimisation processes. MPC enables real-time adjustments to setpoints, and studies have shown it can improve final protein yields and product quality [8].
Digital twins - virtual replicas of physical bioreactors - combine these modelling techniques to simulate and troubleshoot processes virtually. They allow operators to test "what-if" scenarios and evaluate corrective actions in a risk-free environment before making real-world changes. As cultivated meat production processes become more standardised and equipment more uniform, digital twins are expected to play an increasingly important role in routine troubleshooting and process optimisation.
sbb-itb-ffee270
Case Studies: Applications of Predictive Modelling
Examples from industrial cell culture highlight how predictive modelling can address specific bioprocess challenges and offer valuable insights for cultivated meat production.
Nutrient Depletion and Metabolite Accumulation
Managing nutrients effectively is critical in bioprocessing. One study from a cell culture facility created a predictive model that combined multiple linear regression with machine learning. This model was designed to forecast key outputs such as final titre, peak viable cell density, lactate, and ammonia levels early in the production process. Impressively, it accounted for 70–95% of parameter variability. By identifying at-risk batches days ahead of traditional alarms, the model enabled targeted interventions, improving performance and reducing variability [11].
In another case involving fed-batch processes, predictive feeding strategies based on PLS (partial least squares) multivariate models achieved a 30% reduction in lactate accumulation. This improvement translated into a 20% increase in final titres [3]. When integrated with tools like Raman spectroscopy (e.g., in Sartorius ambr bioreactors), real-time monitoring of glucose, viable cell density, and metabolites delivered prediction errors of less than 5% [2][3]. These approaches could be adapted for cultivated meat production, where precise nutrient management is essential for optimising yield and controlling costs.
Oxygen Limitation and Mixing Issues
Maintaining adequate oxygen levels and proper mixing is another critical challenge in bioprocessing. Computational fluid dynamics (CFD) models are widely used to simulate oxygen gradients and mixing patterns in bioreactors. During scale-up, these simulations have identified inefficient impeller designs that create hypoxic zones in cell cultures. By adjusting agitation rates based on CFD findings, oxygen transfer efficiency improved by 20–30%. Some studies reported dissolved oxygen differences exceeding 20–30% between different zones in large reactors [2][7][9].
Additionally, a biologics manufacturer employed a model predictive control (MPC) framework powered by digital twin models. This enabled dynamic adjustments to gas sparging, effectively solving mixing issues and increasing yields by 15% [3][6]. For cultivated meat production, where uniform mixing is vital to avoid nutrient gradients in high-density cultures, these strategies hold significant promise for ensuring consistent tissue quality.
Shear Stress and Cell Viability
Shear stress, caused by impeller action and collisions in stirred systems, can significantly impact cell viability. Predictive models have been used to quantify these mechanical forces and their effects. In microcarrier cultures, stress thresholds were identified, with forces exceeding 0.1 Pa linked to 15–20% reductions in viability for anchorage-dependent cells [2][10]. By optimising bead sizes and agitation speeds, model-guided adjustments reduced shear-induced cell death by 25%, resulting in over 2% higher protein yields and better product quality [2][8][10].
While direct applications in cultivated meat are still developing, similar hybrid models have been proposed to simulate microcarrier dynamics. These could help maintain cell viability above 90% during expansion [6]. These examples demonstrate how predictive modelling not only addresses existing challenges but also enables proactive optimisation, paving the way for improved outcomes in cultivated meat production.
Future Directions and Implementation Considerations
Building on successful case studies, future strategies in cultivated meat production must focus on implementing advanced models alongside cutting-edge equipment and adhering to standardised protocols.
Key Takeaways for Cultivated Meat Producers
For predictive modelling to be effective, three critical components are required. First, integrated sensors play a crucial role in analysing essential parameters simultaneously, ensuring real-time model efficiency. For instance, Raman spectroscopy platforms can monitor glucose levels, viable cell density, and metabolites all at once, enabling precise feedback-control strategies [2][5]. These integrated platforms simplify real-time monitoring, streamline processes, and significantly reduce waste [2].
Second, scale-down modelling allows robust models to be developed on a smaller scale before being applied to commercial bioreactors. These models must maintain high precision, handle noise effectively, and require minimal recalibration when scaled up [2]. Drawing parallels from cell and gene therapy - fields with similar challenges - scale-down data must be validated through production-scale runs to address reliability issues and ensure seamless scaling [2]. Lastly, standardised data protocols aligned with ISA-88 standards are essential. These protocols enable real-time release testing and adaptive model predictive control (MPC), helping predictive models evolve into prescriptive analytics tools [2][3]. Together, these strategies address current challenges and open doors to new advancements.
Research Gaps and Opportunities
Despite progress, several challenges persist. One major issue is the lack of open datasets, which hinders the development of robust, adaptable models for use across varying bioreactor types and scales [2][3][4]. Another challenge is model transferability - many models fail to perform consistently when transitioning from laboratory settings to production environments or when applied to different equipment configurations [2][3][4]. Additionally, there is a weak connection between model predictions and final product quality attributes, such as cell viability and overall yield [2][3][4].
To overcome these hurdles, standardised protocols and shared datasets are needed to improve model adaptability. AI-driven scale-up simulations could help predict behaviour at larger scales, enhancing transferability [4][10]. Hybrid models, which combine data-driven approaches with mechanistic insights, offer untapped potential for managing biological variability [6]. Strengthening the link between model predictions and quality attributes through advanced MPC and sensitivity analysis could enable closed-loop control systems and virtual testing for process adjustments [3][6].
Addressing these gaps will require investment in equipment designed for scalability and precision.
Equipment and Procurement Considerations
For predictive modelling to succeed, specialised equipment capable of creating data-rich environments is essential. Producers should evaluate whether their equipment supports integrated sensors - like Raman spectroscopy devices - and whether it can scale effectively while accommodating automated controls such as MPC [2][3]. Reliable monitoring of critical process parameters is a must for predictive models to function optimally.
A resource like Cellbase, the first specialised B2B marketplace for the cultivated meat industry, can simplify procurement. Cellbase connects industry professionals with verified suppliers of bioreactors, sensors, growth media, and other vital equipment. Offering expertise tailored to cultivated meat production, the platform helps minimise procurement risks and ensures access to tools designed for advanced bioprocess modelling. For the latest pricing details, readers should check the relevant product pages. For R&D teams and production managers, sourcing through Cellbase ensures compatibility with the technical demands of predictive strategies in cultivated meat production.
FAQs
How does predictive modelling support cultivated meat production?
Predictive modelling plays a key role in improving cultivated meat production by spotting potential bioprocess challenges early on and addressing them before they become major problems. This forward-thinking approach helps to reduce downtime, improve efficiency, and maintain consistent product quality.
By examining data from bioprocessing systems, these models can uncover patterns and foresee issues, allowing researchers and production teams to make informed adjustments. The result? Higher yields, less waste, and lower operational costs - all contributing to a more sustainable and dependable cultivated meat production process.
What data is crucial for effective predictive modelling in bioprocess troubleshooting?
Accurate and detailed data are the backbone of effective predictive modelling in bioprocess troubleshooting. The most critical factors to monitor include temperature, pH levels, dissolved oxygen, CO₂ concentrations, glucose levels, biomass measurements, and metabolite profiles.
Gathering high-quality, real-time data on these variables is crucial. It allows researchers and industry professionals to spot potential problems early, ensuring smooth operations and optimising overall bioprocess performance. This proactive approach helps minimise failures and keeps processes running efficiently.
How do hybrid models improve troubleshooting in cultivated meat bioprocesses?
Hybrid models are transforming troubleshooting in cultivated meat bioprocesses by merging mechanistic models with data-driven methods. This combination creates a powerful tool for making accurate predictions about potential issues and fine-tuning critical processes.
With the ability to monitor systems in real time and identify problems early, hybrid models reduce disruptions and improve process management. The result? Greater efficiency, higher yields, and more reliable production systems.









