

Prediktiv modellering omvandlar produktionen av odlat kött genom att identifiera processproblem innan de eskalerar. Genom att analysera historiska och realtidsdata hjälper dessa modeller operatörer att upprätthålla optimala förhållanden över viktiga stadier som celltillväxt, differentiering och mognad. Detta proaktiva tillvägagångssätt minskar misslyckanden, förbättrar avkastningen och säkerställer konsekvent produktkvalitet.
Viktiga insikter:
- Stadier som är benägna för problem: Näringsbrist, syrebrist och skjuvspänning är vanliga risker.
- Modelltyper: Mekanistiska, datadrivna och hybridmodeller erbjuder skräddarsydda lösningar för felsökning.
- Fördelar: Tidig upptäckt av fel, exakt rotorsaksanalys och kontinuerlig processoptimering.
- Databehov: Högkvalitativa, varierade dataset från online-sensorer och offline-analyser är kritiska.
- Tekniker: Verktyg som PCA, PLS och digitala tvillingar förbättrar förutsägelser och processkontroll.
Prediktiv modellering är en datadriven lösning för att hantera utmaningar inom odlad köttproduktion, vilket erbjuder förbättrad konsistens och operativ effektivitet.
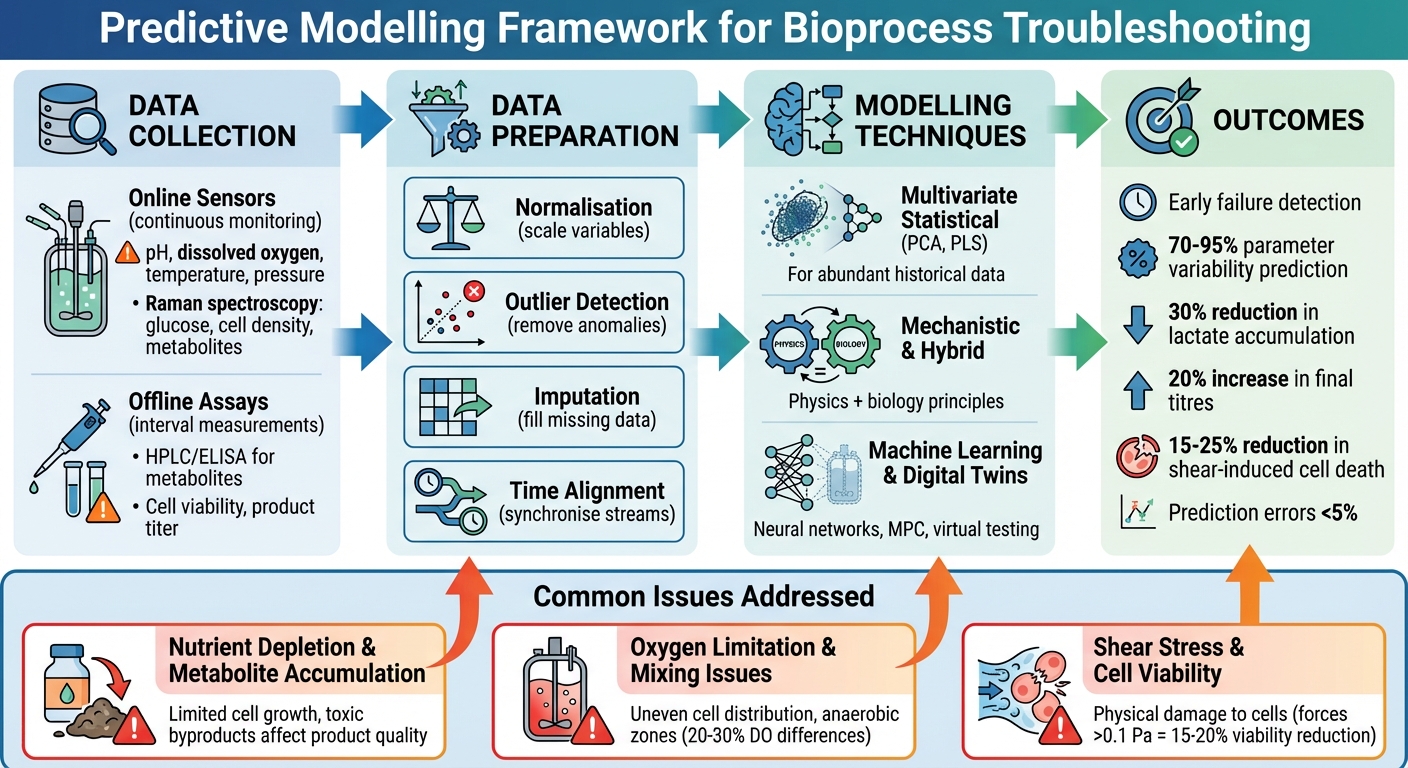
Prediktiv modelleringsramverk för felsökning av bioprocesser för odlat kött
200: Bemästra kvalitet genom design: Från produktmisslyckanden till kommersiell framgång inom biologiska CMC De...
Data krav för prediktiv modellering
Att skapa exakta prediktiva modeller beror på kvaliteten och omfånget av data som samlas in under bioprocessen. Utan detaljerade dataset är det omöjligt för modeller att förutsäga fel eller förbättra prestanda. Det är viktigt att fånga både de fysiska förhållandena inuti bioreaktorn och cellernas biologiska beteenden.Denna grund är avgörande för att förbereda data och tillämpa modelleringstekniker effektivt.
Datakällor i bioprocesser för odlat kött
Prediktiva modeller förlitar sig på två primära datakällor: onlinesensorer och offlinetester.
Onlinesensorer övervakar kontinuerligt realtidsparametrar som pH, löst syre (DO), temperatur och tryck. Vissa avancerade plattformar, såsom Sartorius ambr-system, använder till och med Ramanspektroskopi för att spåra glukosnivåer, livskraftig celldensitet och metaboliter[2][3]. Dessa sensorer tillhandahåller högfrekvent data och fångar de små förändringar som sker inom bioreaktorn.
Offlinetester, å andra sidan, levererar precisa mätningar vid specifika intervall. Tekniker som HPLC eller ELISA används för att bedöma metabolitkoncentrationer (e.g., laktat och ammoniak), cellviabilitet och produkttiter.Medan dessa kräver manuell provtagning och laboratoriearbete, erbjuder de en nivå av precision som online-sensorer kanske inte alltid uppnår[2][3]. Metadata, såsom matningsstrategier och inställningspunkter, hjälper till att tolka sensordata. Till exempel, genom att kombinera Raman-spektroskopidata med matningsprofiler kan multivariata modeller förutsäga kritiska kvalitetsattribut, såsom slutlig titer. Detta möjliggör att modellprediktiva kontrollsystem kan göra justeringar i realtid av bioprocessparametrar[2][3]. Sådana metoder förbättrar modellernas förmåga att felsöka och optimera prestanda.
När data har samlats in måste den bearbetas noggrant för att säkerställa att den kan göra tillförlitliga förutsägelser.
Dataförbehandlingstekniker
Rådata från bioreaktorer är sällan redo att användas i prediktiv modellering.Flera förbehandlingssteg är nödvändiga för att förbereda det:
- Normalisering säkerställer att variabler skalas till jämförbara intervall. Till exempel förhindrar det att parametrar som celldensitet (som ofta har större värden) överskuggar mindre skaliga variabler som pH. Detta steg är särskilt viktigt för algoritmer som partial least squares (PLS)[3].
- Avvikelsedetektering identifierar och tar bort avvikelser orsakade av sensorer, provtagningsfel eller tillfälliga störningar. Statistiska trösklar eller PLS-baserade metoder används ofta för att utesluta dessa avvikelser och förhindra att de snedvrider förutsägelser[3].
- Imputation fyller i saknade datapunkter. Tekniker som imputation genom regression (IBR) använder korrelationer mellan parametrar - till exempel glukos- och laktatnivåer - för att uppskatta luckor.Om DO-data saknas kan modellen förutsäga det baserat på relationer mellan pH och glukos, vilket bevarar datasetets tillförlitlighet för realtidsprognoser[3].
- Tidsjustering synkroniserar datastreams som kanske inte naturligt matchar. Till exempel behöver kontinuerliga pH-avläsningar justeras med metabolitassayresultat tagna vid specifika intervall. Metoder som dynamisk tidskrig eller linjär interpolation används för att säkerställa korrekt justering[3].
Hantering av biologisk variabilitet
Biologisk variabilitet utgör en av de största utmaningarna i produktionen av odlat kött. Skillnader i cellinjer, genetisk drift och varierade reaktioner på näringsbrist leder till inkonsekvenser i tillväxthastigheter och metabolitprofiler från batch till batch[2][4][6].Denna variabilitet kan avsevärt påverka noggrannheten i förutsägelser. Till exempel, om en modell inte är utformad för att ta hänsyn till skillnader mellan cellinjer eller produktionsskalor, kan förutsägelser för livskraftig celldensitet vara helt felaktiga.
För att hantera detta bör producenter samla in diverse historiska dataset som täcker flera cellinjer, mediesammansättningar och bioreaktorskalor. Multivariat statistisk processkontroll (MSPC) kan hjälpa genom att bryta ner variabilitet i systematiska och slumpmässiga komponenter, vilket gör det möjligt för modeller att skilja normala fluktuationer från faktiska problem[3][4][6].
En annan effektiv lösning är användningen av hybridmodeller. Dessa kombinerar mekanistisk kunskap - som Monod-kinetik för celltillväxt - med datadrivna metoder.Denna blandning gör det möjligt för modeller att fånga både de förutsägbara biologiska processerna och de oförutsägbara variationerna som rent mekanistiska modeller kan missa[3][4][6]. Dessutom hjälper användningen av serumfria medier med väldefinierade, djurfria formuleringar att standardisera näringssammansättningar. Detta minskar variabiliteten, vilket resulterar i mer konsekventa data och mer pålitliga prediktiva modeller[1].
Modelleringstekniker för felsökning av bioprocesser
Att välja rätt modelleringsmetod beror på hur väl processen förstås, kvaliteten på tillgängliga data och de specifika fel du vill förutsäga. Varje teknik har sina egna styrkor för felsökning av odlade köttbioprocesser, och de fungerar i harmoni med de tidigare stegen av databeräkning.
Multivariata statistiska modeller
När historiska data är rikliga men de biologiska processerna inte är fullt förstådda, lyser tekniker som Partial Least Squares (PLS) och Principal Component Analysis (PCA). Dessa metoder analyserar flera sammanhängande variabler - såsom temperatur, pH-nivåer, löst syre, omrörningshastigheter och spektroskopidata - och destillerar dem till några få nyckelmönster som representerar normalt processbeteende.
Till exempel etablerar PCA en baslinje med data från framgångsrika satser. Om en ny sats avviker från denna baslinje kan statistik som Hotelling's T² tidigt flagga potentiella problem, vilket gör det möjligt för operatörer att ingripa innan problemen eskalerar. PLS tar detta ett steg längre genom att möjliggöra realtidsprognoser av närings- och metabolitnivåer. Istället för att vänta på offline-analyser kan PLS-modeller förutsäga händelser som glukosutarmning eller laktatuppbyggnad, vilket gör det enklare att proaktivt justera utfodringsscheman.
Ett annat värdefullt verktyg, SIMCA, fyller i saknade data med hjälp av historiska register, vilket säkerställer att luckor i dataset inte hindrar felsökning. Men framgången för dessa modeller beror på att de tränas med olika dataset som speglar variationen över cellinjer, medietyper och produktionsskalor. Detta säkerställer att operatörer snabbt kan identifiera och åtgärda avvikelser under produktionen av odlat kött.
Mekanistiska och Hybridmodeller
När det finns en solid förståelse för den underliggande fysiken och biologin blir mekanistiska modeller - byggda på principer som massbalanser och transportekvationer - oumbärliga. Dessa modeller simulerar nyckelparametrar som syreöverföring, blandningsdynamik och näringsfördelning inom bioreaktorer. De är särskilt användbara under uppskalning, där direkta experiment är kostsamma och tidskrävande.
Inom produktion av odlat kött kan mekanistiska modeller också förutsäga hur skjuvkrafter påverkar celler som är fästa vid mikrobärare eller ställningar. Genom att integrera hydrodynamiska beräkningar med data om cellkänslighet ger dessa modeller insikter i hur förändringar i omrörning eller perfusion kan påverka cellernas livskraft och vävnadskvalitet. Sådana förutsägelser är avgörande för att hantera prestandafall när man övergår till ny utrustning eller skalar upp produktionen.
Hybridmodeller kombinerar styrkorna hos mekanistiska och datadrivna tillvägagångssätt. De använder en mekanistisk ram för fysisk konsistens samtidigt som de lägger till datadrivna komponenter - som neurala nätverk eller PLS - för att ta hänsyn till komplex kinetik som inte är fullt förstådd.Detta är särskilt relevant för odlat kött, där kunskap om celldifferentiering i 3D-ställningar fortfarande utvecklas. Den mekanistiska delen säkerställer tillförlitliga förutsägelser under föränderliga förhållanden, medan det datadrivna lagret anpassar sig till verkligt växtbeteende. Dessa hybridmodeller banar väg för sofistikerade digitala verktyg som diskuteras i nästa avsnitt.
Maskininlärning och digitala tvillingar
Neurala nätverk utmärker sig i att identifiera icke-linjära relationer mellan sensordata och resultat som livskraftig celldensitet eller differentieringsmarkörer. Genom att träna dessa modeller på historiska data kan de fungera som tidiga varningssystem, som upptäcker avvikelser innan de eskalerar till betydande problem.
Modellprediktiv kontroll (MPC) tar detta ett steg längre genom att integrera prediktiva modeller i optimeringsprocesser.MPC möjliggör realtidsjusteringar av börvärden, och studier har visat att det kan förbättra slutliga proteinutbyten och produktkvalitet [8].
Digitala tvillingar - virtuella kopior av fysiska bioreaktorer - kombinerar dessa modelleringstekniker för att simulera och felsöka processer virtuellt. De tillåter operatörer att testa "tänk om"-scenarier och utvärdera korrigerande åtgärder i en riskfri miljö innan verkliga förändringar görs. När processerna för odlat kött blir mer standardiserade och utrustningen mer enhetlig, förväntas digitala tvillingar spela en allt viktigare roll i rutinmässig felsökning och processoptimering.
sbb-itb-ffee270
Fallstudier: Tillämpningar av prediktiv modellering
Exempel från industriell cellkultur belyser hur prediktiv modellering kan hantera specifika bioprocessutmaningar och erbjuda värdefulla insikter för produktion av odlat kött.
Näringsutarmning och metabolitackumulering
Effektiv hantering av näringsämnen är avgörande inom bioprocessering. En studie från en cellkulturanläggning skapade en prediktiv modell som kombinerade multipel linjär regression med maskininlärning. Denna modell var utformad för att förutsäga viktiga resultat som slutlig titer, topp livskraftig celldensitet, laktat och ammoniaknivåer tidigt i produktionsprocessen. Imponerande nog stod den för 70–95% av parametervariabiliteten. Genom att identifiera riskfyllda satser dagar före traditionella larm möjliggjorde modellen riktade interventioner, förbättrade prestanda och minskade variabilitet [11].
I ett annat fall som involverade fed-batch-processer uppnåddes en 30% minskning av laktatackumulering genom prediktiva matningsstrategier baserade på PLS (partial least squares) multivariata modeller. Denna förbättring översattes till en 20% ökning av slutliga titer [3].När de integreras med verktyg som Raman-spektroskopi (e.g., i Sartorius ambr bioreaktorer), levererade realtidsövervakning av glukos, livskraftig celldensitet och metaboliter prediktionsfel på mindre än 5% [2][3]. Dessa metoder kan anpassas för odlad köttproduktion, där exakt näringshantering är avgörande för att optimera avkastning och kontrollera kostnader.
Syrebegränsning och blandningsproblem
Att upprätthålla tillräckliga syrenivåer och korrekt blandning är en annan kritisk utmaning inom bioprocessering. Beräkningsvätskedynamik (CFD) modeller används i stor utsträckning för att simulera syregradienter och blandningsmönster i bioreaktorer. Under uppskalning har dessa simuleringar identifierat ineffektiva omrörardesigner som skapar hypoxiska zoner i cellkulturer. Genom att justera omrörningshastigheter baserat på CFD-resultat förbättrades syreöverföringseffektiviteten med 20–30%.Vissa studier rapporterade skillnader i löst syre som översteg 20–30% mellan olika zoner i stora reaktorer [2][7][9].
Dessutom använde en biologisk tillverkare en modellprediktiv kontroll (MPC) ramverk drivet av digitala tvillingmodeller. Detta möjliggjorde dynamiska justeringar av gasinblåsning, vilket effektivt löste blandningsproblem och ökade avkastningen med 15% [3][6]. För odlad köttproduktion, där enhetlig blandning är avgörande för att undvika näringsgradienter i högdensitetskulturer, har dessa strategier stor potential för att säkerställa konsekvent vävnadskvalitet.
Skjuvspänning och cellviabilitet
Skjuvspänning, orsakad av omrörarens verkan och kollisioner i omrörda system, kan avsevärt påverka cellviabiliteten.Prediktiva modeller har använts för att kvantifiera dessa mekaniska krafter och deras effekter. I mikrobärarkulturer identifierades stressgränser, där krafter som överstiger 0,1 Pa kopplades till 15–20% minskningar i livskraft för fästberoende celler [2][10]. Genom att optimera pärlstorlekar och omrörningshastigheter minskade modellstyrda justeringar skjuvningsinducerad celldöd med 25%, vilket resulterade i över 2% högre proteinutbyten och bättre produktkvalitet [2][8][10].
Även om direkta tillämpningar inom odlat kött fortfarande utvecklas, har liknande hybridmodeller föreslagits för att simulera mikrobärardynamik. Dessa skulle kunna hjälpa till att upprätthålla cellviabilitet över 90% under expansion [6].Dessa exempel visar hur prediktiv modellering inte bara adresserar befintliga utmaningar utan också möjliggör proaktiv optimering, vilket banar väg för förbättrade resultat i produktionen av odlat kött.
Framtida Riktningar och Implementeringsöverväganden
Byggt på framgångsrika fallstudier måste framtida strategier inom produktion av odlat kött fokusera på att implementera avancerade modeller tillsammans med toppmodern utrustning och följa standardiserade protokoll.
Viktiga Insikter för Producenter av Odlat Kött
För att prediktiv modellering ska vara effektiv krävs tre kritiska komponenter. För det första spelar integrerade sensorer en avgörande roll i att analysera väsentliga parametrar samtidigt, vilket säkerställer modellens effektivitet i realtid.Till exempel kan Raman-spektroskopiplattformar övervaka glukosnivåer, livskraftig celldensitet och metaboliter samtidigt, vilket möjliggör precisa feedback-kontrollstrategier [2][5]. Dessa integrerade plattformar förenklar övervakning i realtid, effektiviserar processer och minskar avfall avsevärt [2].
För det andra, nedskalningsexperiment möjliggör utveckling av robusta modeller i mindre skala innan de tillämpas på kommersiella bioreaktorer. Dessa modeller måste bibehålla hög precision, hantera brus effektivt och kräva minimal omkalibrering vid uppskalning [2]. Genom att dra paralleller från cell- och genterapi - områden med liknande utmaningar - måste nedskalningsdata valideras genom produktionsskala körningar för att hantera tillförlitlighetsfrågor och säkerställa sömlös skalning [2].Till sist är standardiserade dataprotokoll i linje med ISA-88-standarder avgörande. Dessa protokoll möjliggör realtidsutsläppstestning och adaptiv modellprediktiv kontroll (MPC), vilket hjälper prediktiva modeller att utvecklas till preskriptiva analysverktyg [2][3]. Tillsammans adresserar dessa strategier nuvarande utmaningar och öppnar dörrar för nya framsteg.
Forskningsluckor och Möjligheter
Trots framsteg kvarstår flera utmaningar. Ett stort problem är bristen på öppna dataset, vilket hindrar utvecklingen av robusta, anpassningsbara modeller för användning över olika bioreaktortyper och skalor [2][3][4]. En annan utmaning är modellöverförbarhet - många modeller misslyckas med att prestera konsekvent när de övergår från laboratoriemiljöer till produktionsmiljöer eller när de tillämpas på olika utrustningskonfigurationer [2][3][4]. Dessutom finns det en svag koppling mellan modellens förutsägelser och slutliga produktkvalitetsattribut, såsom cellviabilitet och total avkastning [2][3][4].
För att övervinna dessa hinder behövs standardiserade protokoll och delade dataset för att förbättra modellens anpassningsförmåga. AI-drivna uppskalningssimuleringar kan hjälpa till att förutsäga beteende i större skala, vilket förbättrar överförbarheten [4][10].Hybridmodeller, som kombinerar datadrivna metoder med mekanistiska insikter, erbjuder outnyttjad potential för att hantera biologisk variabilitet [6]. Att stärka länken mellan modellprediktioner och kvalitetsattribut genom avancerad MPC och känslighetsanalys kan möjliggöra sluten styrsystem och virtuell testning för processjusteringar [3][6].
Att åtgärda dessa luckor kommer att kräva investeringar i utrustning utformad för skalbarhet och precision.
Utrustning och Inköpsöverväganden
För att prediktiv modellering ska lyckas är specialiserad utrustning som kan skapa datarika miljöer avgörande.Producenter bör utvärdera om deras utrustning stöder integrerade sensorer - som Raman-spektroskopi-enheter - och om den kan skalas effektivt samtidigt som den rymmer automatiserade kontroller som MPC [2][3]. Tillförlitlig övervakning av kritiska processparametrar är ett måste för att prediktiva modeller ska fungera optimalt.
En resurs som
Vanliga frågor
Hur stödjer prediktiv modellering produktionen av odlat kött?
Prediktiv modellering spelar en nyckelroll i att förbättra produktionen av odlat kött genom att tidigt identifiera potentiella bioprocessutmaningar och åtgärda dem innan de blir större problem. Detta framåtblickande tillvägagångssätt hjälper till att minska stillestånd, förbättra effektiviteten och bibehålla en konsekvent produktkvalitet.
Genom att undersöka data från bioprocessystem kan dessa modeller avslöja mönster och förutse problem, vilket gör det möjligt för forskare och produktionsteam att göra informerade justeringar. Resultatet? Högre avkastning, mindre avfall och lägre driftskostnader - allt bidrar till en mer hållbar och pålitlig produktion av odlat kött.
Vilken data är avgörande för effektiv prediktiv modellering vid felsökning av bioprocesser?
Exakt och detaljerad data är ryggraden i effektiv prediktiv modellering vid felsökning av bioprocesser. De mest kritiska faktorerna att övervaka inkluderar temperatur, pH-nivåer, lösta syre, CO₂-koncentrationer, glukosnivåer, biomassmätningar, och metabolitprofiler.
Att samla in högkvalitativ, realtidsdata om dessa variabler är avgörande. Det gör det möjligt för forskare och branschproffs att upptäcka potentiella problem tidigt, vilket säkerställer smidiga operationer och optimerar den övergripande bioprocessprestandan. Detta proaktiva tillvägagångssätt hjälper till att minimera fel och håller processerna igång effektivt.
Hur förbättrar hybridmodeller felsökning i bioprocesser för odlat kött?
Hybridmodeller omvandlar felsökning i bioprocesser för odlat kött genom att kombinera mekanistiska modeller med datadrivna metoder. Denna kombination skapar ett kraftfullt verktyg för att göra exakta förutsägelser om potentiella problem och finjustera kritiska processer.
Med förmågan att övervaka system i realtid och identifiera problem tidigt, minskar hybridmodeller störningar och förbättrar processhanteringen. Resultatet? Större effektivitet, högre avkastning och mer tillförlitliga produktionssystem.









