

Forudsigende modellering transformerer produktionen af dyrket kød ved at identificere procesproblemer, før de eskalerer. Ved at analysere historiske og realtidsdata hjælper disse modeller operatører med at opretholde optimale betingelser på tværs af nøglefaser som cellevækst, differentiering og modning. Denne proaktive tilgang reducerer fejl, forbedrer udbyttet og sikrer ensartet produktkvalitet.
Vigtige punkter:
- Faser udsat for problemer: Næringsstofudtømning, iltmangel og skærestress er almindelige risici.
- Modeltyper: Mekanistiske, datadrevne og hybride modeller tilbyder skræddersyede løsninger til fejlfinding.
- Fordele: Tidlig fejldetektion, præcis årsagsanalyse og kontinuerlig procesoptimering.
- Databehov: Højkvalitets, forskelligartede datasæt fra online sensorer og offline analyser er kritiske.
- Teknikker: Værktøjer som PCA, PLS og digitale tvillinger forbedrer forudsigelser og proceskontrol.
Forudsigende modellering er en datadrevet løsning til at tackle udfordringer i produktionen af dyrket kød, hvilket tilbyder forbedret konsistens og operationel effektivitet.
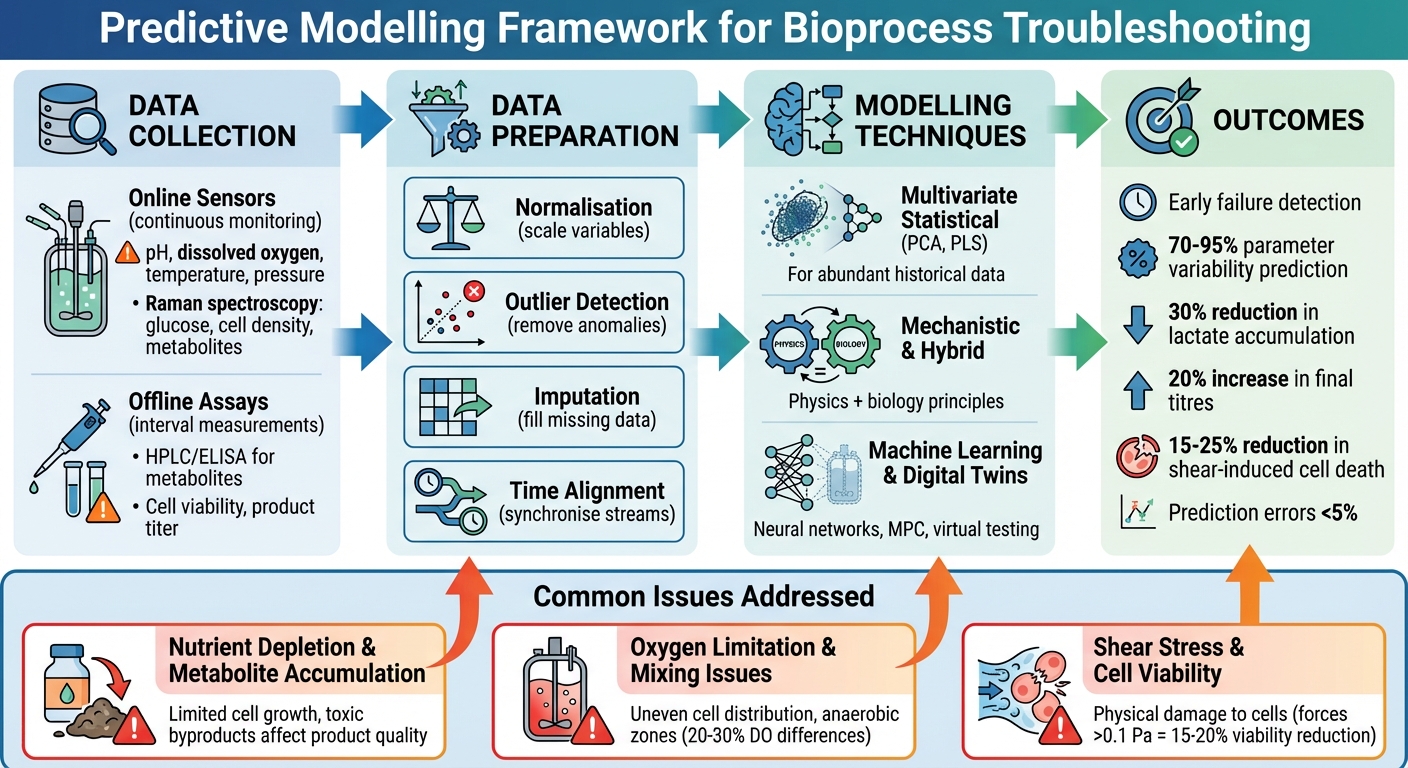
Forudsigende modelleringsramme for fejlfinding i bioprocesser for dyrket kød
200: Mestring af kvalitet ved design: Fra produktfejl til kommerciel succes i biologics CMC De...
Data krav til forudsigende modellering
Oprettelse af nøjagtige forudsigende modeller afhænger af kvaliteten og omfanget af data indsamlet under bioprocessen. Uden detaljerede datasæt er det umuligt for modeller at forudsige fejl eller forbedre ydeevnen. Det er essentielt at indfange både de fysiske forhold inde i bioreaktoren og cellernes biologiske adfærd.Denne foundation er afgørende for at forberede data og anvende modelleringsteknikker effektivt.
Datakilder i dyrkede kød-bioprocesser
Prædiktive modeller er afhængige af to primære datakilder: online sensorer og offline assays.
Online sensorer overvåger kontinuerligt realtidsparametre som pH, opløst ilt (DO), temperatur og tryk. Nogle avancerede platforme, såsom Sartorius ambr systemer, bruger endda Raman spektroskopi til at spore glukoseniveauer, levedygtig celletæthed og metabolitter[2][3]. Disse sensorer leverer højfrekvente data, der fanger de små ændringer, der sker inden for bioreaktoren.
Offline assays, derimod, leverer præcise målinger på specifikke intervaller. Teknikker som HPLC eller ELISA bruges til at vurdere metabolitkoncentrationer (e.g., laktat og ammoniak), cellelevedygtighed og produkttiter.Mens disse kræver manuel prøvetagning og laboratoriearbejde, tilbyder de et præcisionsniveau, som online sensorer måske ikke altid opnår[2][3]. Metadata, såsom fodringsstrategier og indstillingspunkter, hjælper med at fortolke sensordata. For eksempel tillader kombinationen af Raman-spektroskopidata med fodringsprofiler multivariate modeller at forudsige kritiske kvalitetsattributter, såsom endelig titer. Dette gør det muligt for modelprædiktive kontrolsystemer at foretage realtidsjusteringer af bioprocesparametre[2][3]. Sådanne tilgange forbedrer modellernes evne til at fejlfinde og optimere ydeevnen.
Når dataene er indsamlet, skal de behandles omhyggeligt for at sikre, at de kan give pålidelige forudsigelser.
Dataforbehandlingsteknikker
Rå bioreaktordata er sjældent klar til brug i prædiktiv modellering.Flere forbehandlingsskridt er nødvendige for at forberede det:
- Normalisering sikrer, at variabler skaleres til sammenlignelige intervaller. For eksempel forhindrer det parametre som celletæthed (som ofte har større værdier) i at overskygge mindre skala-variabler som pH. Dette skridt er især vigtigt for algoritmer som partial least squares (PLS)[3].
- Outlier-detektion identificerer og fjerner anomalier forårsaget af sensorstøj, prøveudtagningsfejl eller midlertidige forstyrrelser. Statistiske tærskler eller PLS-baserede metoder anvendes ofte til at udelukke disse outliers, hvilket forhindrer dem i at forvride forudsigelser[3].
- Imputation udfylder manglende datapunkter. Teknikker som imputation ved regression (IBR) bruger korrelationer mellem parametre - for eksempel glukose- og laktatniveauer - til at estimere huller.Hvis DO-data mangler, kan modellen forudsige det baseret på forholdet mellem pH og glukose, hvilket bevarer datasættets pålidelighed til realtidsprognoser[3].
- Tidsjustering synkroniserer datastrømme, der måske ikke naturligt passer sammen. For eksempel skal kontinuerlige pH-aflæsninger tilpasses med metabolitassayresultater taget på specifikke intervaller. Metoder som dynamisk tidskrig eller lineær interpolation bruges til at sikre korrekt justering[3].
Håndtering af biologisk variabilitet
Biologisk variabilitet udgør en af de største udfordringer i produktionen af dyrket kød. Forskelle i cellelinjer, genetisk drift og varierede reaktioner på næringsstofmangel fører til uoverensstemmelser i vækstrater og metabolitprofiler fra batch til batch[2][4][6].Denne variabilitet kan betydeligt påvirke nøjagtigheden af forudsigelser. For eksempel, hvis en model ikke er designet til at tage højde for forskelle mellem cellelinjer eller produktionsskalaer, kan forudsigelser for levedygtig celletæthed være helt forkerte.
For at tackle dette bør producenter indsamle diverse historiske datasæt, der dækker flere cellelinjer, mediesammensætninger og bioreaktorskalaer. Multivariat statistisk proceskontrol (MSPC) kan hjælpe ved at nedbryde variabilitet i systematiske og tilfældige komponenter, hvilket gør det muligt for modeller at skelne normale udsving fra faktiske problemer[3][4][6].
En anden effektiv løsning er brugen af hybridmodeller. Disse kombinerer mekanistisk viden - som Monod-kinetik for cellevækst - med datadrevne metoder.Denne blanding gør det muligt for modeller at fange både de forudsigelige biologiske processer og de uforudsigelige variationer, som rent mekanistiske modeller måske overser[3][4][6]. Derudover hjælper anvendelsen af serumfri medier med veldefinerede, dyrefri formuleringer med at standardisere næringssammensætninger. Dette reducerer variabilitet, hvilket resulterer i mere konsistente data og mere pålidelige forudsigelsesmodeller[1].
Modelleringsteknikker til fejlfinding i bioprocesser
Valg af den rigtige modelleringsmetode afhænger af, hvor godt processen forstås, kvaliteten af de tilgængelige data, og de specifikke fejl, du ønsker at forudsige. Hver teknik bringer sine egne styrker til fejlfinding af dyrkede kød-bioprocesser, og de arbejder i harmoni med de tidligere trin i databehandlingen.
Multivariate Statistiske Modeller
Når historiske data er rigelige, men de biologiske processer ikke er fuldt ud forstået, skinner teknikker som Partial Least Squares (PLS) og Principal Component Analysis (PCA). Disse metoder analyserer flere indbyrdes forbundne variable - såsom temperatur, pH-niveauer, opløst ilt, omrøringshastigheder og spektroskopidata - og destillerer dem til nogle få nøglemønstre, der repræsenterer normal procesadfærd.
For eksempel etablerer PCA en baseline ved hjælp af data fra succesfulde batches. Hvis en ny batch afviger fra denne baseline, kan statistikker som Hotelling's T² tidligt markere potentielle problemer, hvilket giver operatører mulighed for at gribe ind, før problemerne eskalerer. PLS tager dette et skridt videre ved at muliggøre realtidsforudsigelser af næringsstof- og metabolitniveauer.I stedet for at vente på offline analyser, kan PLS-modeller forudsige begivenheder som glukoseudtømning eller laktatophobning, hvilket gør det lettere at justere fodringsplaner proaktivt.
Et andet værdifuldt værktøj, SIMCA, udfylder manglende data ved hjælp af historiske optegnelser, hvilket sikrer, at huller i datasæt ikke hindrer fejlfinding. Dog afhænger succesen af disse modeller af at træne dem med forskellige datasæt, der afspejler variationen på tværs af cellelinjer, medietyper og produktionsskalaer. Dette sikrer, at operatører hurtigt kan identificere og adressere afvigelser under produktionen af dyrket kød.
Mekanistiske og Hybride Modeller
Når der er en solid forståelse af den underliggende fysik og biologi, bliver mekanistiske modeller - bygget på principper som massebalancer og transportligninger - uundværlige. Disse modeller simulerer nøgleparametre som iltoverførsel, blandingsdynamik og næringsfordeling inden for bioreaktorer.De er særligt nyttige under opskalering, hvor direkte eksperimenter er dyre og tidskrævende.
Ved produktion af dyrket kød kan mekanistiske modeller også forudsige, hvordan skærekræfter påvirker celler, der er fastgjort til mikrobærere eller stilladser. Ved at integrere hydrodynamiske beregninger med data om cellernes følsomhed giver disse modeller indsigt i, hvordan ændringer i omrøring eller perfusion kan påvirke cellelevedygtighed og vævskvalitet. Sådanne forudsigelser er afgørende for at imødegå præstationsfald, når man overgår til nyt udstyr eller opskalerer produktionen.
Hybridmodeller kombinerer styrkerne fra mekanistiske og datadrevne tilgange. De bruger en mekanistisk ramme for fysisk konsistens, mens de tilføjer datadrevne komponenter - som neurale netværk eller PLS - for at tage højde for komplekse kinetikker, der ikke er fuldt ud forstået. Dette er især relevant for dyrket kød, hvor viden om celledifferentiering i 3D stilladser stadig udvikles. Den mekanistiske del sikrer pålidelige forudsigelser under skiftende forhold, mens det datadrevne lag tilpasser sig virkelige planteadfærd. Disse hybride modeller baner vejen for sofistikerede digitale værktøjer, der diskuteres i det næste afsnit.
Maskinlæring og Digitale Tvillinger
Neurale netværk udmærker sig ved at identificere ikke-lineære relationer mellem sensordata og resultater såsom levedygtig celletæthed eller differentieringsmarkører. Ved at træne disse modeller på historiske data kan de fungere som tidlige advarselssystemer, der opdager anomalier, før de eskalerer til betydelige problemer.
Model Predictive Control (MPC) tager dette et skridt videre ved at indlejre forudsigelsesmodeller i optimeringsprocesser.MPC muliggør realtidsjusteringer af indstillingspunkter, og undersøgelser har vist, at det kan forbedre de endelige proteinafkast og produktkvalitet [8].
Digitale tvillinger - virtuelle kopier af fysiske bioreaktorer - kombinerer disse modelleringsteknikker for at simulere og fejlfinde processer virtuelt. De giver operatører mulighed for at teste "hvad-nu-hvis"-scenarier og evaluere korrigerende handlinger i et risikofrit miljø, før der foretages ændringer i den virkelige verden. Efterhånden som produktionen af dyrket kød bliver mere standardiseret og udstyret mere ensartet, forventes digitale tvillinger at spille en stadig vigtigere rolle i rutinemæssig fejlfinding og procesoptimering.
sbb-itb-ffee270
Case Studies: Applications of Predictive Modelling
Eksempler fra industriel cellekultur fremhæver, hvordan prædiktiv modellering kan tackle specifikke bioprocesudfordringer og tilbyde værdifulde indsigter til produktion af dyrket kød.
Næringsstofudtømning og Metabolitakkumulering
Effektiv styring af næringsstoffer er afgørende i bioprocessering. En undersøgelse fra et cellekulturanlæg skabte en forudsigelsesmodel, der kombinerede multipel lineær regression med maskinlæring. Denne model var designet til at forudsige nøgleudgange som endelig titer, maksimal levedygtig celletæthed, laktat og ammoniakniveauer tidligt i produktionsprocessen. Imponerende nok tog den højde for 70–95% af parametervariabiliteten. Ved at identificere risikobatches dage før traditionelle alarmer, muliggjorde modellen målrettede interventioner, forbedrede ydeevnen og reducerede variabilitet [11].
I et andet tilfælde, der involverede fed-batch-processer, opnåede forudsigende fodringsstrategier baseret på PLS (partial least squares) multivariate modeller en 30% reduktion i laktatakkumulering. Denne forbedring oversattes til en 20% stigning i endelige titere [3].Når integreret med værktøjer som Raman-spektroskopi (e.g., i Sartorius ambr bioreaktorer), leverede realtidsmonitorering af glukose, levedygtig celletæthed og metabolitter forudsigelsesfejl på mindre end 5% [2][3]. Disse tilgange kunne tilpasses til produktion af dyrket kød, hvor præcis næringsstofstyring er afgørende for at optimere udbytte og kontrollere omkostninger.
Oxygenbegrænsning og blandingsproblemer
At opretholde tilstrækkelige iltniveauer og korrekt blanding er en anden kritisk udfordring i bioprocessering. Computational fluid dynamics (CFD) modeller anvendes bredt til at simulere iltgradienter og blandingsmønstre i bioreaktorer. Under opskalering har disse simulationer identificeret ineffektive impellerdesigns, der skaber hypoxiske zoner i cellekulturer. Ved at justere omrøringshastigheder baseret på CFD-resultater forbedredes iltoverførselseffektiviteten med 20–30%.Nogle undersøgelser rapporterede forskelle i opløst ilt, der oversteg 20–30% mellem forskellige zoner i store reaktorer [2][7][9].
Derudover anvendte en biologisk producent en modelprædiktiv kontrol (MPC) ramme drevet af digitale tvillingemodeller. Dette gjorde det muligt at foretage dynamiske justeringer af gasindblæsning, hvilket effektivt løste blandingsproblemer og øgede udbyttet med 15% [3][6]. For produktion af dyrket kød, hvor ensartet blanding er afgørende for at undgå næringsstofgradienter i høj-densitetskulturer, har disse strategier betydelig potentiale for at sikre ensartet vævskvalitet.
Skærspænding og Cellelevedygtighed
Skærspænding, forårsaget af impelleraktion og kollisioner i omrørte systemer, kan have en betydelig indvirkning på cellelevedygtighed.Forudsigelsesmodeller er blevet brugt til at kvantificere disse mekaniske kræfter og deres effekter. I mikrocarrier-kulturer blev stressgrænser identificeret, hvor kræfter, der overstiger 0,1 Pa, var forbundet med 15–20% reduktioner i levedygtighed for forankringsafhængige celler [2][10]. Ved at optimere perlestørrelser og omrøringshastigheder reducerede modelstyrede justeringer shear-induceret celledød med 25%, hvilket resulterede i over 2% højere proteinafkast og bedre produktkvalitet [2][8][10].
Mens direkte anvendelser i dyrket kød stadig er under udvikling, er lignende hybridmodeller blevet foreslået til at simulere mikrocarrier-dynamik. Disse kunne hjælpe med at opretholde cellelevedygtighed over 90% under ekspansion [6].Disse eksempler viser, hvordan prædiktiv modellering ikke kun adresserer eksisterende udfordringer, men også muliggør proaktiv optimering, hvilket baner vejen for forbedrede resultater i produktionen af dyrket kød.
Fremtidige Retninger og Implementeringsovervejelser
Med udgangspunkt i succesfulde casestudier skal fremtidige strategier i produktionen af dyrket kød fokusere på at implementere avancerede modeller sammen med banebrydende udstyr og overholde standardiserede protokoller.
Vigtige Læringer for Producenter af Dyrket Kød
For at prædiktiv modellering skal være effektiv, kræves tre kritiske komponenter. For det første spiller integrerede sensorer en afgørende rolle i at analysere væsentlige parametre samtidigt, hvilket sikrer realtidsmodel effektivitet.For eksempel kan Raman-spektroskopi platforme overvåge glukoseniveauer, levedygtig celletæthed og metabolitter på én gang, hvilket muliggør præcise feedback-kontrolstrategier [2][5]. Disse integrerede platforme forenkler realtidsmonitorering, strømliner processer og reducerer affald betydeligt [2].
For det andet, muliggør skaleringsned eksperimenter robuste modeller at blive udviklet i mindre skala, før de anvendes på kommercielle bioreaktorer. Disse modeller skal opretholde høj præcision, håndtere støj effektivt og kræve minimal rekalibrering, når de skaleres op [2]. Ved at drage paralleller fra celle- og genterapi - felter med lignende udfordringer - skal skaleringsned data valideres gennem produktionsskala kørsel for at adressere pålidelighedsproblemer og sikre problemfri skalering [2].Til sidst er standardiserede dataprotokoller i overensstemmelse med ISA-88-standarder essentielle. Disse protokoller muliggør realtidsudgivelsestestning og adaptiv modelprædiktiv kontrol (MPC), hvilket hjælper prædiktive modeller med at udvikle sig til præskriptive analysetools [2][3]. Sammen adresserer disse strategier aktuelle udfordringer og åbner døre til nye fremskridt.
Forskningshuller og muligheder
På trods af fremskridt vedvarer flere udfordringer. Et stort problem er manglen på åbne datasæt, hvilket hæmmer udviklingen af robuste, tilpasningsdygtige modeller til brug på tværs af forskellige bioreaktortyper og skalaer [2][3][4]. En anden udfordring er modeloverførbarhed - mange modeller fejler i at præstere konsekvent, når de overgår fra laboratorieindstillinger til produktionsmiljøer eller når de anvendes på forskellige udstyrskonfigurationer [2][3][4]. Derudover er der en svag forbindelse mellem modelprediktioner og endelige produktkvalitetsattributter, såsom cellelevedygtighed og samlet udbytte [2][3][4].
For at overvinde disse forhindringer er der behov for standardiserede protokoller og delte datasæt for at forbedre modellens tilpasningsevne. AI-drevne opskaleringssimuleringer kunne hjælpe med at forudsige adfærd i større skalaer, hvilket forbedrer overførbarheden [4][10].Hybridmodeller, der kombinerer datadrevne tilgange med mekanistiske indsigter, tilbyder uudnyttet potentiale til at håndtere biologisk variabilitet [6]. Styrkelse af forbindelsen mellem modelprediktioner og kvalitetsattributter gennem avanceret MPC og følsomhedsanalyse kunne muliggøre lukkede kontrolsystemer og virtuel testning for procesjusteringer [3][6].
At adressere disse huller vil kræve investering i udstyr designet til skalerbarhed og præcision.
Udstyrs- og Indkøbs Overvejelser
For at prædiktiv modellering skal lykkes, er specialiseret udstyr, der er i stand til at skabe data-rige miljøer, essentielt.Producenter bør evaluere, om deres udstyr understøtter integrerede sensorer - som Raman-spektroskopi-enheder - og om det kan skaleres effektivt, mens det imødekommer automatiserede kontroller som MPC [2][3]. Pålidelig overvågning af kritiske procesparametre er et must for, at prædiktive modeller kan fungere optimalt.
En ressource som
Ofte stillede spørgsmål
Hvordan understøtter forudsigende modellering produktionen af dyrket kød?
Forudsigende modellering spiller en nøglerolle i forbedringen af produktionen af dyrket kød ved at identificere potentielle bioprocesudfordringer tidligt og adressere dem, før de bliver større problemer. Denne fremadskuende tilgang hjælper med at reducere nedetid, forbedre effektiviteten og opretholde en ensartet produktkvalitet.
Ved at undersøge data fra bioprocessystemer kan disse modeller afdække mønstre og forudse problemer, hvilket giver forskere og produktionsteams mulighed for at foretage informerede justeringer. Resultatet? Højere udbytte, mindre spild og lavere driftsomkostninger - alt sammen bidrager til en mere bæredygtig og pålidelig produktion af dyrket kød.
Hvilke data er afgørende for effektiv prædiktiv modellering i bioprocesfejlfinding?
Præcise og detaljerede data er rygraden i effektiv prædiktiv modellering i bioprocesfejlfinding. De mest kritiske faktorer at overvåge inkluderer temperatur, pH-niveauer, opløst ilt, CO₂-koncentrationer, glukoseniveauer, biomassemålinger, og metabolitprofiler.
Indsamling af høj-kvalitets, realtidsdata om disse variabler er afgørende. Det giver forskere og branchefolk mulighed for at opdage potentielle problemer tidligt, sikre smidige operationer og optimere den samlede bioprocesydelse. Denne proaktive tilgang hjælper med at minimere fejl og holder processerne kørende effektivt.
Hvordan forbedrer hybridmodeller fejlfinding i bioprocesser for dyrket kød?
Hybridmodeller transformerer fejlfinding i bioprocesser for dyrket kød ved at kombinere mekanistiske modeller med datadrevne metoder. Denne kombination skaber et kraftfuldt værktøj til at lave præcise forudsigelser om potentielle problemer og finjustere kritiske processer.
Med evnen til at overvåge systemer i realtid og identificere problemer tidligt reducerer hybridmodeller forstyrrelser og forbedrer processtyring. Resultatet? Større effektivitet, højere udbytte og mere pålidelige produktionssystemer.









